install.packages("tidyverse")Introdução
Neste livro teremos vários exemplos de transformação e manipulação de dados utilizando os pacotes da linguagem R. O principal pacote que iremos utilizar chamado tidyverse. Ele é uma espécie de “super pacote” para ciência de dados e contém outros pacotes que auxiliam nas atividades relativas à esta prática, como importação, transformação, manipulação, modelagem e visualização de dados.

Para saber mais sobre este pacote, acesse:
https://cran.r-project.org/package=tidyverse
Para os exemplos, estamos assumindo que você já possui o R instalado e preferencialmente um ambiente de desenvolvimento para R como RStudio ou VSCode.
Para instalar o pacote, digite:
Uma vez o pacote instalado, precisamos referenciá-lo em nossos scripts, ou no jargão do R, devemos carregar o pacote tidyverse. Para isto, digite o código a seguir:
library (tidyverse)Folhas de Referências
A maioria dos exemplos, visam ajudar na interpretação dos exemplos e funções encontradas na Folha de Referência dos pacotes (cheatsheets) disponível no site do RStudio.
A seguir, um exemplo de uma “Folha de Referência” do pacote DPLYR:
![]()
Ao longo das apresentações das Folhas de Resumo e respectivos capítulos sobre os pacotes, iremos lidar com nomenclaturas que são muito comuns no âmbito da ciência de dados e estatística, mas podem não ser comuns para outras áreas da ciência ou dos negócios, portanto, iremos apresentar algumas delas brevemente para que você possa acompanhar de forma mais clara os capítulos seguintes.
Variáveis e Observações
Apesar de comumente associarmos o termo variável à valores do campo da matemática, como álgebra, ela também é usado em muitos outros campos do conhecimento, como o da computação, estatística, etc.
Neste livro utilizaremos o termo “variável” no contexto de ciência de dados e estatística. Iremos definí-la como uma característica da população que pode ser categorizada, medida ou contada .
Sem entrarmos em maiores detalhes e simplificando para o melhor entendimento deste conteúdo, pense em uma tabela, com colunas e linhas. Em geral, quando temos dados organizados (veremos o que caracteriza um dado organizado mais adiante), as variáveis são colocadas em colunas. Já nas linhas da tabela, teremos o que é conhecido como casos, ou observações.
Apesar de não serem sinônimos, ou não representarem o mesmo objeto, utilizaremos de forma intercambiável e sem o rigor acadêmico, os termos: coluna e variável assim como observações e linhas.
Portanto, quando em alguma parte do texto, você ler algo como “a variável xyz”, pode traduzir em sua mente para algo como “a coluna xyz”. Quando ler algo como “as 10 primeiras observações” , poder traduzir para “as 10 primeiras linhas” e assim por diante.
Entendemos que desta forma, o leitor mais inciantes entenderá o conceito daquilo que estamos apresentando, e o leitor mais avançado, o fará da mesma forma.
Tipos de Variáveis
Como dito anteriormento, não é intuito deste tópico aprofundar neste tema, porém como a natureza dos dados para manipulação e até mesmo cada gráfico podem estar relacionadas ao tipo de variável que ele irá representar, vamos rever de forma resumida os tipos de variáveis no contexto de análise de dados.
Podemos categorizar as variáveis em Qualitativas ou Quantitativas. (Fávero 2021)
Qualitativas
Representam as características de um indivíduo, objeto ou elemento que não podem ser medidas ou quantificadas.
As variáveis qualitativas, também poder ser classificadas em função do número de categorias em:
Dicotômica ou Binária: Apenas duas categorias.
Policotômica: Mais que duas categorias.
Ou em função da escala de mensuração em:
Nominal: As unidades são classificadas em categorias em relação à características representadas. Sem ordem ou relação entre si. (ex: sexo)
Ordinal: As unidades são classificadas em categorias em relação à características representadas. Há uma ordem ou relação entre si. (ex: grau de escolaridade)
Tipicamente, um dado qualitativo em natureza representa valores discretos que pertencem a um conjunto finito de classes. Estes valores discretos podem ser representados através de um número ou textos.
Quantitativa
Representam as características de um indivíduo, objeto ou elemento resultantes de uma contagem ou mensuração.
As variáveis quantitativas, também podem ser classificadas em função da escala de precisão.
Discreta: Assumem conjunto finito de valores, frequentemente de uma contagem (ex: número de filhos, quantidade de carros, etc)
Contínua: Assumem conjunto infinito de valores, frequentemente com resultado de uma mensuração (ex: peso, altura, salário, etc)
Ou em função da escala de mensuração em:
Intervalar: As unidades são ordenadas em relação à características mensurada e possui um unidade de constante. A origem, ou ponto zero, não expressa ausência de quantidade. (ex: temperatura)
Razão: As unidades são ordenadas em relação à características mensurada e possui um unidade de constante. A origem, ou ponto zero, é única e expressa ausência de quantidade.(ex: distância percorrida)
Cuidado
Vale lembrar que nem sempre uma variável representada por um número é quantitativa. O número da carteira de identidade é um exemplo disso. Apesar dos números ela é uma variável qualitativa.
Exemplo
Para ficar mais claro como estas classificações de variáveis serão utilizadas ao longo do livro, vejamos alguns exemplos utilziando a tabela chamada “MPG” abaixo:
mpgEsta tabela, possui dados de economia de combustíveis entre 1999 a 2008 de 38 modelos populares de carros.
Ela possui 234 observações (linhas) e 11 variáveis (colunas).
Vejamos algumas delas.
glimpse(mpg)Rows: 234
Columns: 11
$ manufacturer <chr> "audi", "audi", "audi", "audi", "audi", "audi", "audi", "…
$ model <chr> "a4", "a4", "a4", "a4", "a4", "a4", "a4", "a4 quattro", "…
$ displ <dbl> 1.8, 1.8, 2.0, 2.0, 2.8, 2.8, 3.1, 1.8, 1.8, 2.0, 2.0, 2.…
$ year <int> 1999, 1999, 2008, 2008, 1999, 1999, 2008, 1999, 1999, 200…
$ cyl <int> 4, 4, 4, 4, 6, 6, 6, 4, 4, 4, 4, 6, 6, 6, 6, 6, 6, 8, 8, …
$ trans <chr> "auto(l5)", "manual(m5)", "manual(m6)", "auto(av)", "auto…
$ drv <chr> "f", "f", "f", "f", "f", "f", "f", "4", "4", "4", "4", "4…
$ cty <int> 18, 21, 20, 21, 16, 18, 18, 18, 16, 20, 19, 15, 17, 17, 1…
$ hwy <int> 29, 29, 31, 30, 26, 26, 27, 26, 25, 28, 27, 25, 25, 25, 2…
$ fl <chr> "p", "p", "p", "p", "p", "p", "p", "p", "p", "p", "p", "p…
$ class <chr> "compact", "compact", "compact", "compact", "compact", "c…Dentre as variáveis, observamos uma variável qualitativa nominal chamada “manufacturer” que categoriza o fabricante do veículo.
Já a variável “hwy”, que representa o consumo na estrada (em milhas por galão), pode ser categorizada como uma variavel quantitativa continua. Por exemplo, determinado veículo consegue fazer 25.73 milhas por galão.
Nota
No caso específico desta base de dados MPG, vemos que, a variável “hwy” está representada por um tipo inteiro <int>, ao invés de um tipo double <dbl>, isto nos leva a supor que ela foi “arredondada” para o valor mais próximo de milhas e portanto, devemos classificá-la como quantitativa discreta para sermos mais precisos.
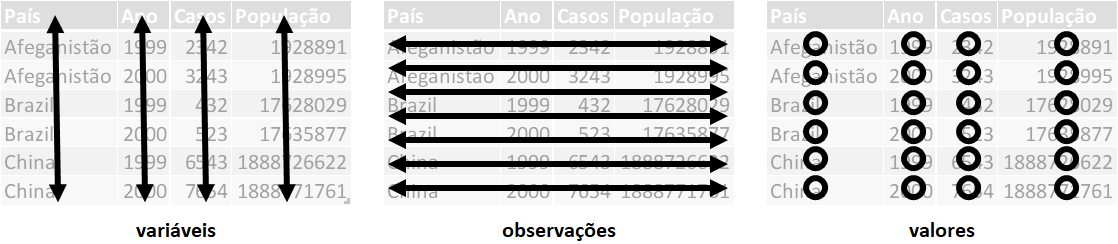
Dados Organizados (Tidy)
Dados organizados (tidy) são estruturados onde:
Cada variável está em sua própria coluna e cada observação está em sua própria linha.
Canalização (Piping)
A canalização (Piping) é uma forma de sequenciar as funções, facilitando a leitura de várias funções em conjunto.
O símbolo |> é utilizado para esta finalidade.
Exemplo: x |> f(y), é o mesmo que f(x,y)
Nota
O símbolo %>% do pacote magrittr também faz a função similar de pipe como o |> do R básico, porém com algumas vantagens. Como não precisamos utilizar nada além do pipe básico, a maioria do código deste conteúdo utiliza o |>.
Exemplo:
# Escrever este código sem o Pipe (|>)
head(mtcars, 5)
#É o mesmo que escrever com o Pipe desta forma:
mtcars |> head(5)No exemplo acima, pode não parecer muito vantajoso, mas quando nosso código faz diversas manipulações, o uso da canalização (pipe) ajuda na leitura e interpretação do código.
Vetores
Vetores é um tipo básico de objeto na linguagem R. Existem seis tipos de vetores atômicos no R:
lógicos (logical)
inteiros (integer)
duplos (doubles)
complexos (complex)
caractere (character)
bruto (raw)
Quando criamos apenas um valor, ele retorna um vetor de tamanho = 1.
Por exemplo:
# Vetor atômico de caractere
print("abc")[1] "abc"# Vetor atômico de inteiro
print(90L)[1] 90Vetore com múltiplos valores:
Podemos criar vetores de múltiplos valores com algumas funções. Por exemplo, para criar um vetor duplo em uma sequência númerica de 1.00 até 2.00, incrementando as cada 0.25, podemos usar a função seq():
seq(1.00, 2.00, by = 0.25)[1] 1.00 1.25 1.50 1.75 2.00
Dica
Podemos utilizar dois-pontos (:) para criar uma vetor de múltiplos valores númerico no R também:
5:10[1] 5 6 7 8 9 10Para criarmos um vetor múltiplo, onde valores que não são do tipo caractere são convertidos para caratectere, podemos usar a função c().
c(5, TRUE, "banana")[1] "5" "TRUE" "banana"Veja que as aspas acima em “5” e “TRUE”, definem um tipo caractere e não mais inteiro ou lógico.
Para acessar elementos de um vetor, podemos usar colchetes e o respectivo índice do elemento (começando em 1).
dia_semana <- c("Seg", "Ter", "Qua", "Qui", "Sex", "Sab", "Dom")
dia_semana_num <- dia_semana[c(1,2,5)]
dia_semana_num[1] "Seg" "Ter" "Sex"Podemos acessar também passando um vetor lógico. Veja o exemplo:
dia_semana[c(TRUE, TRUE, FALSE, FALSE, TRUE, FALSE, FALSE)][1] "Seg" "Ter" "Sex"Estas informações introdutórias farão mais sentido quando as utilzarmos mais adiante nos capítulos seguintes. Por hora, basta conhecê-las para entendê-las quando elas aparecerem nos códigos seguintes.
Fávero, Belfiore, Luiz P. 2021. "Manual de Análise de Dados". Comput. J., dezembro.