library (tidyverse)
library (readxl)
library (googlesheets4)
library (openxlsx)1 Importação de Dados com TIDYVERSE
1.1 Introdução
A seguir temos vários exemplos de importação de dados utilizando o pacote TIDYVERSE do R. O pacote tidyverse possui vários pacotes de importação de dados, aqui iremos cobrir três deles (readr, readxl e googlesheets4). Para saber mais sobre estes pacotes, acesse:
https://cran.r-project.org/package=tidyverse.
https://cran.r-project.org/package=readr.
https://cran.r-project.org/package=readxl.
https://cran.r-project.org/package=googlesheets4.
Os pacotes acima, serão utilzados para importação de dados tabulados (ex: .CSV ou TXT), planilhas do Excel e do Google.
Caso você precise trabalhar com outras formatos de arquivos que não sejam os vistos neste capítulo, pode buscar maiores informações sobre os pacotes a seguir:
| Pacote | Formato |
|---|---|
| haven | Arquivos SPSS, Stata e SAS |
| DBI | Bancos de Dados |
| jsonlite | JSON |
| xml2 | XML |
| httr | Web APIs |
| rvest | HTML (Web scraping) |
| readr::read_lines() | dados texto |
| pdftools |
Para os exemplos, iremos carregar os seguintes pacotes:
tidyverse
readxl
googlesheets4
openxlsx
1.1.1 Exemplos da Folha de Referência
A maioria dos exemplos, visam ajudar na interpretação dos exemplos e funções encontradas na Folha de Referência de importação de dados com tidyverse disponível no site do RStudio.


1.1.2 Arquivos
Para a maioria dos exemplos utilizaremos os seguintes arquivos de dados:
Alguns desses arquivos são baseados nas tabelas mtcars, storms e starwars provenientes do pacote datasets e dplyr e também algumas tabelas (Table1, 2, 3, 4a, 4b e 5) que vem com o pacote tidyr.
ARQUIVOS TABULADOS: (TXT, CSV, TSV e FWF):
Iremos criar os arquivos tabulados para que possamos usá-los posteriormente. Para isso, execute o código abaixo:
write_file("A|B|C\n1|2|3\n4|5|NA", file = "file.txt")
write_file("A,B,C\n1,2,3\n4,5,NA", file = "file.csv")
write_file("A;B;C\n1,5;2;3\n4,5;5;NA", file = "file2.csv")
write_file("A\tB\tC\n1\t2\t3\n4\t5\tNA\n", file = "file.tsv")EXCEL_FILE.XLSX:
A seguir, você tem um link para o arquivo Excel utilizado nos exemplos.
É um arquivo com três planilhas (S1, S2 e S3) e em cada uma delas um pequeno conjunto de dados.
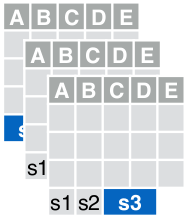
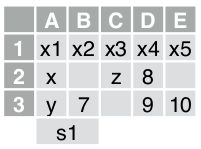
E a primeira planilha (S1) possui algo como:
GOOGLE_SHEET:
A seguir, você tem o link para a planilha do google que será utilizado mais adiante.
Planilha exemplo - Google Sheets
1.2 READR
O pacote readr possui diversas funções para ler dados tabulados (ex: .csv, .tsv, .txt, etc). Estas funções começam com read_*().
read_* (file, col_names = TRUE, col_types = NULL, col_select = NULL, id = NULL, locale, n_max = Inf, skip = 0, na = c(““,”NA”), guess_max = min(1000, n_max), show_col_types = TRUE)
Os parametros acima, são comuns à estas funções. Veja a seguir algumas delas. Digite ?read_delim para obter maiores detalhes de como utilzá-las.
1.2.1 Ler dados tabulados com readr
1.2.1.1 read_delim
Use para ler um arquivo tabulado com qualquer delimitador. Se nenhum delimitador é especificado, a função tentará advinhar automaticamente.
Por exemplo, para ler um arquivo .TXT tabulado com o caractere “|” como delimitador, fazemos:
read_delim("file.txt", delim = "|")
Dica
Para armazenar a leitura do arquivo em um objeto no R, podemos usar o operador <-.
meu_arquivo_csv <-read_delim("file.txt", delim = "|")
meu_arquivo_csv1.2.1.2 read_cvs
Use para ler um arquivo tabulado separado por vírgula. Esta função entende que casas decimais que usam o ponto (ex 1.00) como separador de casas decimais.
read_csv("file.csv") 1.2.1.3 read_cvs2
Use para ler um arquivo tabulado separado por ponto-e-vírgula. Esta função entende que casas decimais que usam a vírgula (ex: 1,00) como separador de casas decimais.
read_csv2("file2.csv") 1.2.1.4 read_tsv
Use para ler um arquivo tabulado separado por tab.
read_tsv("file.tsv") 1.2.1.5 read_fwf
Use para ler um arquivo tabulado com tamanhos fixos de colunas.
Nota
Veja que a largura das colunas deve ser passada como um vetor para a parametro col_positions = usando a função fwf_width().
read_fwf("file.tsv", fwf_widths(c(2,2,NA)))1.2.2 Parâmetros Úteis
Alguns parametros das funções read_*() são muito úteis durante o processo de leitura pois permitem controlar melhor o que iremos obter como resultado da leitura.
1.2.2.1 Sem cabeçalho
Use o parâmetro COL_NAMES para não trazer a primeira linha como nome das colunas.
read_csv2("file2.csv", col_names = FALSE) 1.2.2.2 Definir cabeçalho
Use o parâmetro COL_NAMES para definir manualmente os nomes das colunas.
read_csv("file.csv", col_names = c("X", "Y", "Z")) 1.2.2.3 Ler vários arquivos
Use o parametro ID para ler multiplos arquivos e armazená-los em uma mesma tabela.
write_file("A,B,C\n1,2,3\n4,5,NA", file = "f1.csv")
write_file("A,B,C\n6,7,8\n9,10,11", file = "f2.csv")
read_csv(c("f1.csv", "f2.csv"), id = "arq_origem")
Importante
Observe que as colunas dos diversos arquivos devem corresponder, ou seja, ter o mesmo nome de colunas.
1.2.2.4 Pular linhas
Use o prâmetro SKIP para pular as primeiras n linhas.
read_csv("file.csv", skip = 1) 1.2.2.5 Ler um número máximo de linhas
Use o prâmetro N_MAX para ler um número máximo de linhas.
read_csv("file.csv", n_max = 1) 1.2.2.6 Ler valores como NA
Use o prâmetro NA para definir um ou mais valores como NA.
read_csv("file.csv", na = c("1")) 1.2.2.7 Especificar caractere decimal
Use o prâmetro LOCALE para definir o caractere de casa decimais.
read_delim("file2.csv", locale = locale(decimal_mark = ",")) 1.2.3 Salvar dados com readr
Similar às funções descritas na seção “Ler dados tabulados com readr” usadas para ler os aqruivos de texto tabulados, temos o conjunto de funções write_*() para gravar os arquivos correspondentes. Estas funções seguem o seguinte padrão:
write_*(x, file, na = “NA”, append, col_names, quote, escape, eol, num_threads, progress)
As principais funções são:
1.2.3.1 write_delim
Use para gravar um arquivo delimitado por algum caractere específico. O parametro delim= permite definir este caractere. O caracteres padrão é o espaço (” “).
Por exemplo, se quisermos gravar uma tabela (tibble) em um arquivo .txt delimitado por ponto-e-vírgula”;“, podemos usar:
conteudo <- tribble(~col_A, ~col_B,
1, "A",
2, "B",
3, "C")
write_delim(conteudo, file = "arquivo_exemplo1.txt", delim=";")1.2.3.2 write_csv
Use para gravar uma tabela em uma arquivo delimitado por “vírgula”.
Dica
Podemos usar o arqumento na = para definirmos qual valor será usando para os valore ausentes, por padrão é utilizado “NA”. No exemplo a seguir, iremos trocar por “NULL”.
conteudo <- tribble(~col_A, ~col_B,
1, "A",
2, "B",
3, NA,
4, "D")
write_csv(conteudo, file = "arquivo_exemplo2.csv", na = "NULL")1.2.3.3 write_csv2
Use para gravar uma tabela em um arquivo delimitado por “ponto-e-vírgula”.
Dica
Pode usar o parametro “col_names =” para incluir ou não os nomes das colunas no arquivo de saída. No exemplo a seguir, não iremos incluir os nomes das colunas:
conteudo <- tribble(~col_A, ~col_B,
1, "A",
2, "B",
3, "C")
write_csv2(conteudo, file = "arquivo_exemplo3.csv", col_names = FALSE)1.2.3.4 write_tsv
Use para gravar uma tabela em um arquivo delimitado por “TAB”:
conteudo <- tribble(~col_A, ~col_B,
1, "A",
2, "B",
3, "C")
write_tsv(conteudo, file = "arquivo_exemplo4.tsv")1.2.4 Especificação de colunas com readr
Ao importar um arquivo com readr, podemos definir qual o tipo de coluna que determinado dado será importado. Por padrão, o readr irá gerar a especificação de cada coluna quando o arquivo form lido e gerará um resumo na saída.
Podemos usar o argumento spec() para extrair as especificações das colunas de um arquivo importato para um data frame.
Por exemplo:
arq <- read_csv2("file2.csv")
spec(arq)cols(
A = col_double(),
B = col_double(),
C = col_double()
)Observe que as colunas “A”, “B” e “C” são do formato double.
Há também uma mensagem de resumo ao importar um arquivo. Observe que ele informa o delimitador utilzado, mas também a especificação das colunas, neste caso, tipo double (dbl) para as colunas A, B e C conforme confirmamos com a função spec().
ℹ Using “‘,’” as decimal and “‘.’” as grouping mark. Use read_delim() for more control. Rows: 2 Columns: 3── Column specification ────────────────────────────────────────────────────────────────── Delimiter: “;” dbl (3): A, B, C ℹ Use spec() to retrieve the full column specification for this data. ℹ Specify the column types or set show_col_types = FALSE to quiet this message. # READXL
Dica
Se quisermos omitir as especificações das colunas da mensagem de saída, usamos o parametro show_col_types = FALSE
1.2.4.1 col_types
Se utilizarmos o parametro col_types = podemos definir, por exemplo, a coluna “B” como inteiro (integer). Veja:
arq <- read_csv2("file2.csv", col_types = "did")
spec(arq)cols(
A = col_double(),
B = col_integer(),
C = col_double()
)Há uma letra definida para cada tipo de coluna que quisermos especificar, veja a lista abaixo:
• col_logical() - “l”
• col_integer() - “i”
• col_double() - “d”
• col_number() - “n”
• col_character() - “c”
• col_factor(levels, ordered = FALSE) - “f”
• col_datetime(format = ““) -”T”
• col_date(format = ““) -”D”
• col_time(format = ““) -”t”
• col_skip() - “-”, “_”
• col_guess() - “?”
Por isso, usamos string “did” para definir um double, um inteiro e outro double para as colunas que importamos.
Podemos também passar a especificação das colunas como uma lista mesclando as funções e os caracteres correspondentes na lista acima.
Por exemplo:
arq <- read_csv2("file2.csv",
col_types = list(A = col_double(), B = "i", C= "d")
)
spec(arq)cols(
A = col_double(),
B = col_integer(),
C = col_double()
)
Dica
Use “.default =” na lista de especificações para definir o tipo padrão para as colunas, caso as mesmas não sejam explicitamente definidas.
1.2.4.2 col_select
Para selecionarmos apenas algumas colunas para importar do arquivo, utilzamos o parametro col_select = passanto um vetor com o nomes das colunas.
Por exemplo, para importar apenas as colunas “A” e “C”, podemos fazer:
read_csv("file.csv", col_select = c("A", "C"))1.2.4.3 guess_max
Para definirmos o número máximo de linhas do arquivo para advinhar o tipo da coluna (guess), utilizamos o parametro guess_max =. O padrão são as primeiras 1000 linhas.
read_csv("file.csv",guess_max = 2)1.3 READXL
Para lermos arquivos do Microsoft Excel, podemos usar o pacote readxl.
1.3.1 Ler arquivos do Excel
Apesar do pacote readxl ser instalado quando instalamos o pacote tidyverse, ele não é carregado quando carregamos o tidyverse. É por isso, que tivemos o código “library (readxl) na seção Introdução
1.3.1.1 read_excel
Use para ler um arquivo do Excel (.xls ou .xlsx) baseado na extensão do arquivo.
Se preferir, pode utilizar as funções read_xls() e read_xlsx() para ler um arquivo com .xls ou .xlsx independente da extensão do arquivo.
read_excel("excel_file.xlsx")1.3.2 Ler planilhas
Sabemos que um arquivo Excel (workbook), pode conter uma ou mais planilhas (worksheets). Para definirmos as planilhas que precisamos importar, podemos utilizar o parametros sheet = da função read_excel(). Podemos passar uma string com o nome a planilha (ex: “S1”) ou um índice númerico pela ordem de criação da planilha (ex: 1). Se nada for especificado, padrão é trazer a primeira planilha.
read_excel("excel_file.xlsx", sheet = "S1")Para obter os nomes das planilhas presentes no arquivo, utilizamos a função excel_sheets()
excel_sheets("excel_file.xlsx")[1] "S1" "S2" "S3"
Dica
Para lermos múltiplas planilhas podemos obter os nomes das planilhas usando a função excel_sheets(), pois definimos os nomes do vetor iguais aos nomes das planilhas e finalmente utilizamos a função purrr::map_dfr() para importar os arquivos no data frame.
arq <- "excel_file.xlsx"
arq |>
excel_sheets() |>
set_names() |>
map_dfr(read_excel, path = arq)1.3.3 Especificação de colunas
Para especificar os tipos das colunas no data frame após a importação do arquivo, usamos o parametro col_types =, similar ao que fizemos para arquivos tabulados na seção Especificação de colunas com readr.
Os tipos de colunas podemos ser:
“skip”, “guess”, “logical”, “numeric”, “date”, “text” ou “list”.
Dica
Use uma coluna de lista (list-column) descrita no pacote tidyr para trabalhar com colunas com vários tipos.
1.3.4 Outros pacotes
Além do pacote readxl, há outros pacotes muito úteis para criar arquivos do MS Excel, tais como:
openxlsx
writexl
Para trabalhar com dados do Excel de forma não tabular, veja o pacote:
- tidyxl
1.3.5 Especificação de celulas
Use os argumentos range = para a função read_excel() ou googlesheets4::read_sheet() no caso de planilhas do Google para ler um subconjunto de células de uma planilha.
Por exemplo, se quiser ler apenas o range de células de “A1” até “B3” da planilha “S2” do arquivo excel de exemplo, por fazer:
read_excel("excel_file.xlsx", range = "S2!A1:B3")O parametro range = , possui alguns argumentos que ajudam a melhor definir o range a ser importado. Veja ?`cell-specification` para maiores detalhes de como cell_cols(), cell_rows(), cell_limits() e anchored(). Por exemplo, usando cell_cols, podemos definir que iremos importar apenas as celulas que das colunas “B” até “D”:
read_excel("excel_file.xlsx", sheet = "S1",
range = cell_cols("B:D"))1.4 GOOGLESHEETS4
1.4.1 Ler planilhas
1.4.1.1 read_sheet
Use para ler planilhas do Google a partir de uma URL, um IDde planilha ou um objeto do tipo “dribble” que é retornado pelo pacote googledrive. Esta função é um “apelido” para a função range_read() que é mais utilizada no contexto do pacote googlesheets4.
Diversos argumtos vistos para as funções read_* são aplicadas aqui também, como col_types = , sheet =, range = , guess_max = . Veja mais detalhes na seção do readr descrita anteriormente.
No exemplo a seguir iremos ler uma planilha do Google de exemplo. Para isso, recebemos o seguinte URL. Veja que a partes em negrito corresponde ao ID do arquivo e o ID da planilha respectivamente:
https://docs.google.com/spreadsheets/d/1_aRR_9UcMytZqjID0BkJ7PW29M1kt1_x2HxhBZOlFN8/edit#gid=0
Usamos então a função read_sheet():
googlesheets4::read_sheet("1_aRR_9UcMytZqjID0BkJ7PW29M1kt1_x2HxhBZOlFN8", sheet = "Sheet1")
Cuidado
A primeira vez que executar este comendo, haverá um processo de autenticação da sua conta do Google e seeão do R. Reponda “Yes” para a pergunta “Is it OK to cache OAuth access credentials in the folder ~/.cache/gargle between R sessions?”
1: Yes
2: No
Depois o navegador será aberto solicitando o acesso aos arquivo do Google. Selecoine o checkbox e click em “Continue”.
1.4.2 Metadados das planilhas
1.4.2.1 gs4_gets
Use para obter os metadados do arquivo:
gs4_get("1_aRR_9UcMytZqjID0BkJ7PW29M1kt1_x2HxhBZOlFN8")Spreadsheet name: tidyverse_exemplo
ID: 1_aRR_9UcMytZqjID0BkJ7PW29M1kt1_x2HxhBZOlFN8
Locale: en_US
Time zone: America/Sao_Paulo
# of sheets: 68
(Sheet name): (Nominal extent in rows x columns)
Sheet1: 1000 x 26
df: 4 x 2
Sheet2: 4 x 2
Sheet3: 4 x 2
Sheet4: 4 x 2
Sheet5: 4 x 2
Sheet6: 4 x 2
Sheet7: 4 x 2
Sheet8: 4 x 2
Sheet9: 4 x 2
Sheet10: 4 x 2
Sheet11: 4 x 2
Sheet12: 4 x 2
Sheet13: 4 x 2
Sheet14: 4 x 2
Sheet15: 4 x 2
Sheet16: 4 x 2
Sheet17: 4 x 2
Sheet18: 4 x 2
Sheet19: 4 x 2
Sheet20: 4 x 2
Sheet21: 4 x 2
Sheet22: 4 x 2
Sheet23: 4 x 2
Sheet24: 4 x 2
Sheet25: 4 x 2
Sheet26: 4 x 2
Sheet27: 4 x 2
Sheet28: 4 x 2
Sheet29: 4 x 2
Sheet30: 4 x 2
Sheet31: 4 x 2
Sheet32: 4 x 2
Sheet33: 4 x 2
Sheet34: 4 x 2
Sheet35: 4 x 2
Sheet36: 4 x 2
Sheet37: 4 x 2
Sheet38: 4 x 2
Sheet39: 4 x 2
Sheet40: 4 x 2
Sheet41: 4 x 2
Sheet42: 4 x 2
Sheet43: 4 x 2
Sheet44: 4 x 2
Sheet45: 4 x 2
Sheet46: 4 x 2
Sheet47: 4 x 2
Sheet48: 4 x 2
Sheet49: 4 x 2
Sheet50: 4 x 2
Sheet51: 4 x 2
Sheet52: 4 x 2
Sheet53: 4 x 2
Sheet54: 4 x 2
Sheet55: 4 x 2
Sheet56: 4 x 2
Sheet57: 4 x 2
Sheet58: 4 x 2
Sheet59: 4 x 2
Sheet60: 4 x 2
Sheet61: 4 x 2
Sheet62: 4 x 2
Sheet63: 4 x 2
Sheet64: 4 x 2
Sheet65: 4 x 2
Sheet66: 4 x 2
Sheet67: 4 x 21.4.2.2 gs4_find
Use para localizar suas planilhas do Google no drive. Ela retorna um objeto dibble, que é um “tibble” com uma linha por arquivo. E informa o ID dos arquivos.
my_dribble <- gs4_find(pattern = "tidyverse_exemplo")
my_dribblesheet_properties
Use para obter uma tabela (tibble) com as propriedades de cada planilha.
sheet_properties("1_aRR_9UcMytZqjID0BkJ7PW29M1kt1_x2HxhBZOlFN8")
Dica
Você pode usar a função sheet_names() para obter os nomes da planilha dentro do arquivo.
1.4.3 Gravar planilhar
O pacote googlesheets4 tem várias maneiras de gravar dados em uma planilha.
1.4.3.1 write_sheet
Use esta função para salvar um data frame em uma planilha no arquivo do Google Sheets. Se a planilha não existir, ele cria uma planilha co mum nome aleatório através da função gs4_create().
df <- tribble(~x, ~y,
1, "A",
2, "B",
3, "C")
write_sheet(df, "1_aRR_9UcMytZqjID0BkJ7PW29M1kt1_x2HxhBZOlFN8")
read_sheet("1_aRR_9UcMytZqjID0BkJ7PW29M1kt1_x2HxhBZOlFN8", sheet = "df")1.4.3.2 gs4_create
Use para criar uma nova planilha do Google. Você pode fornecer o nome, mas caso não o faça o Google irá atribuir um nome aleatorio ao seu arquivo.
minha_planilha <- gs4_create(name = "meu_novo_arquivo_google_sheet", sheets = "Sheet1")
sheet_properties(minha_planilha)1.4.4 Especificação de colunas
Para especificar os tipos das colunas no data frame após a importação da planilha do Google, usamos o parametro col_types = como argumento da função read_sheet/range_read(), similar ao que fizemos para arquivos tabulados na seção Especificação de colunas com readr.
Os tipos de colunas aceitos são:
• skip - “_” ou “-”
• guess - “?”
• logical - “l”
• integer - “i”
• double - “d”
• numeric - “n”
• date - “D”
• datetime - “T”
• character - “c”
• list-column - “L”
• cell - “C” Retorna uma lista bruta dos dados das células.
1.4.5 Especificação de celulas - Google Sheets
Ver seção Especificação de celulas
1.4.6 Operadores de arquivos
O pacote googlesheets4 oferece várias forma de manipular os aspectos da planilha como congelar linhas, definir largura das colunas, etc. Acesse googlesheets4.tidyverse.org para mais informações.
Para operções de arquivos (ex: renomear, compartilhar, mover para outra pasta, etc), veja o pacote googledrive no link: googledrive.tidyverse.org.
1.5 BÔNUS
1.5.1 Web Scraping
1.5.1.1 rvest
Apesar de não termos nada a este respeito na Folha de Referência, acreditamos ser importante ter uma pequena noção de como carregar dados da web utilizando o pacote RVEST. Esta é uma pequena introduzir a obviamente não visa esgotar este assunto, mas sim, mostra um pouco sobre as possibildiades de importação de dados da Web.
Para este exemplo, iremos utilizar uma tabela disponível no Wikipedia no endereço abaixo.
URL: Campeonato_Brasileiro_Serie_A
Esta tabela possui um ranking de pontos dos clubes que jogaram a séria A de futebol brasileiro entre 1959 e 2019.
Após termos definido o endereço da Web que iremos importar, devemos selecionar a tag HTML da tabela em questão. Este é um processo que pode ser bastante complexo, principalmente quando temos sites dinâmicos.
Dica
Para facilitar este processo, sugerimos instalar a extensão no navegador Chrome chamada “SelectorGadget”. Com ele você pode obter o seletor CSS ou string XPATH ao invés de criá-la manualmente. Note que é um facilitador, mas pode não funcionar para todos os casos. Para saber um pouco mais sobre como criar as stirng XPATH para encontrar seu objeto na página, acesse: XPath para raspagem de dados ou Tutorial XPATH.
Uma vez identificado o seletor da tabela, iremos utilizar a função read_html() para carregar oobjeto através do pacote rvest.
Depois, iremos carregar os elementos definidos em nossa string XPATH e então transformá-las em tabelas utilizando a função html_table().
library(rvest)
#Define a URL
url <- read_html("https://en.wikipedia.org/wiki/Campeonato_Brasileiro_S%C3%A9rie_A#Most_appearances")
#Pega as tabelas da página (usando xpath)
tabelas <- url |>
html_elements(xpath = '//*[@id="mw-content-text"]/div/table/tbody') |>
html_table()
#Pega a quinta tabela que é a de nosso interesse
tabelas[[5]]