library (tidyverse)2 Organização de Dados com TIDYR
2.1 Introdução
A seguir temos vários exemplos de organização de dados utilizando o pacote TIDYR do R. Para saber mais sobre este pacote, acesse:
https://cran.r-project.org/package=tidyr.
Para os exemplos, iremos carregar os seguintes pacotes:
- tidyverse
2.1.1 Exemplos da Folha de Referência
A maioria dos exemplos, visam ajudar na interpretação dos exemplos e funções encontradas na Folha de Referência do tidyr disponível no site do RStudio.


2.1.2 Conjunto de Dados
Para a maioria dos exemplos utilizaremos as bases de dados mtcars, storms e starwars provenientes do pacote datasets e dplyr e também algumas tabelas (Table1, 2, 3, 4a, 4b e 5) que vem com o pacote tidyr.
MTCARS: Dados de consumo de combustível, performance e design de 32 automóveis ( 1974 Motor Trend US magazine)
mtcars |>
head () STORMS: Dados de furacões entre 1975-2020 medidos a cada 6 horas durante cada tempestade ( NOAA Atlantic hurricane database ),
storms |>
head () STARWARS: Dados dos personagens de STAR WARS
starwars |>
select(1:8) |>
head()TABELAS EXEMPLOS - Table1, 2, 3, 4a, 4b e 5
table1table2table3table4atable4btable5
Nota
O termo data-frame descrito ao longo deste texto, é utilizado de forma livre para objetos do tipo data.frame, tibble, entre outros. Pense como se fosse uma tabela de um banco de dados e/ou uma planilha do MS Excel, contendo linhas e colunas. Apesar de não ser rigorosamente igual à uma tabela, muitas vezes usaremos estes termos de forma intercambiável para facilitar o entendimento de iniciantes.
2.1.3 Dados Organizados
Conforme visto anteriorment, dados organizados (tidy) são estruturados onde:
Cada variável está em sua própria coluna e cada observação está em sua própria linha.
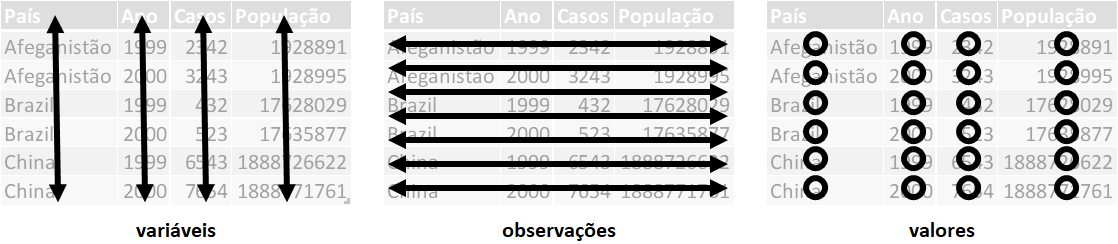
As variáveis (ou colunas) são acessadas como vetores.
Os observações (ou linhas) são preservadas em operações vetorizadas, ou seja, quando utilizamos funções que recebem vetores na entrada e retornam vetores na sua saída.
2.2 Tibbles
Podemos considerar que “Tibbles” são objetos similares aos “Data Frames”, porém com algumas melhorias/vantagens. Estes objetos são fornecidos pelo packago tibble. Eles herdam a classe data frame, mas possuem alguns comportamentos melhorados, como:
Extrai parte de um tibble usando colchetes ] e um vetor com duplo colchetes ]] ou $
Sem encontros parciais quando extraindo partes das colunas
Mostram uma resumo mais amigável na tela quando pedimos suas informações. Use options(tibble.print_max = n, tibble.print_min = m, tibble.width = Inf) para controlar a saída padrão.
As funções View() ou glimpse() permitem visualizar todo o conjunto de dados.
Por exemplo, se tivermos um tibble (ex starwars) e quisermos acessar a coluna “name”, e obter um vetor, podemos usar:
starwars[["name"]] #Por nome com [[ ]]
starwars$name #Por nome com $
starwars[[1]] #Por numero da coluna com [[ ]]Já se tivermos um tibble (ex starwars) e quisermos acessar a coluna “name”, e obter um tibble, podemos usar:
starwars[ , 1] #Por numero com [ ]
select (starwars, 3) #Por numero usando select()
select (starwars, name) #Por nome usando select()2.2.1 Criando tibble
Podemos utilziar as funções tibble() ou tribble() para criar a mesma tabela. A diferença é apenas na forma em que os parêmetros são utilizados.
2.2.1.1 tibble
Use para criar um tibble por colunas.
tibble(x = 1:3, y = c("a", "b", "c"))2.2.1.2 tribble
Use para criar um tibble por linhas.
tribble(~x, ~y,
1, "a",
2, "b",
3, "c",
4, "d")2.2.1.3 as_tibble
Use para converter um data frame para um tibble.
Por exemplo, para converter o data frame MTCARS para um tibble, fazemos:
as_tibble(mtcars)2.2.1.4 enframe
Use para converter um vetor para um tibble. Use deframe() parta fazer o inverso.
2.2.1.5 is_tibble
Use para saber se um objeto é um tibble ou não.
is_tibble(mtcars)[1] FALSE2.3 Reformatando Dados
Muitas vezes, os dados que recebemos não estão organizados (tidy) da maneira como vimos na seção [Dados Organizados e Canalização]. Para casos onde temos, por exemplo, as variáveis em linhas e/ou observações em colunas, etc, precisamos fazer uma ação conhecida como “pivotagem”. Pivotar dados, no contexto do tidyr, significa ajustar linhas em colunas e/ou colunas em linhas, de forma a obtermos nossos dados da maneira organizada (tidy).
Veja, por exemplo, nossa tabela 1 (table1). Ela está em um formato organizado, pois possui cada variável em uma coluna e cada observações em sua linha, com os valores nas células.
table12.3.0.1 pivot_longer
Use para “pivotar” os dados das colunas para as linhas, alongando a tabela, juntando várias colunas em duas, sendo uma a colunas que receberá os nomes das colunas e outra que recebera os valores das colunas.
Por exemplo, vejamos nossa tabela 4 (table4).
table4aObserve que temos uma variável (potencialmente “Ano”) que está na colunas 2 e 3 da tabela. Temos também outra variável (potencialmente “Numero_de_Casos” que está nas células da tabela.
Para organizar esta tabela em nosso formato “tidy”, devemos pegar estas duas colunas e usar a função pivot_longer definindo os nomes para as respectivas variáveis (ex: ano e num_caso).
pivot_longer(table4a, cols = 2:3, names_to ="ano",
values_to = "num_casos") 2.3.0.2 pivot_wider
Use para “pivotar” os dados das linhas para as colunas, expandindo a tabela gerando novas colunas.
Vejamos o caso da tabela 2 (table2).
table2Neste exemplo, vemos que as variáveis casos (cases) e população (population) estão nas linhas e não nas colunas. Para deixarmos os dados organizados (tidy), devemos “expandir” a tabela, fazendo com que os dados de duas colunas sejam expandidos em vaŕias colunas. Os nomes das novas colunas virão de uma colunas e os valores da outra coluna. Veja:
table2 |>
pivot_wider(names_from = type, values_from = count) 2.4 Expandindo Tabelas
Em algumas situações, precisamos criar novas combinações das variáveis ou identificar valores ausentes implícitos, ou seja, combinações de variáveis não presentes nos dados.
Para isto, temos as funções expand() e complete().
2.4.0.1 expand
Use para criar um novo tibble com todas as possibilidades de combinações dos valores das variáveis passadas para a função expand(), ignorando as demais variáveis.
Por exemplo, se quisermos obter todas as combinações possíveis entre o número de cilindros (cyl), marchas (gear) e numero de carburadores (carb) da tabela mtcars, e ignorar todas as demais variáveis da tabela, podemos usar:
mtcars |>
expand(cyl, gear, carb) Observe que não há na tabela original (mtcars) um veículo de 4 cilindros e 8 carburadores, porém esta combinação foi possível usando a função expand().
2.4.0.2 complete
Use para criar um novo tibble com todas as possibilidades de combinações dos valores das variáveis passadas para a função expand(), colocando NA nas demais variáveis.
Por exemplo, se quisermos obter todas as combinações possíveis entre o número de cilindros (cyl), marchas (gear) e numero de carburadores (carb) da tabela mtcars, e colocar NA para as demais variáveis em que a combinação não exista, podemos usar:
mtcars |>
complete(cyl, gear, carb) 2.5 Combinando e Dividindo Celulas
Use as funções a seguir para dividir ou combinar células da tabela em valores individuais isolados.
2.5.0.1 unite
Use para combinar celulas de diversas colunas em uma única coluna.
Vejamos com é a tabela 5 (table5) em seu formato original:
table5 Agora queremos unir as colunas “century” e “year” em uma única coluna:
table5 |>
unite(century, year, col = "ano_completo", sep = "")
Nota
Veja que as colunas que deram origem à coluna combinada não são retornadas na saída da função.
2.5.0.2 separate
Use para dividir cada célula de uma coluna em várias colunas.
Por exemplo, na tabela 3 (table3), temos uma coluna “rate” que possui daos dos casos e população separados por uma barr (“/”). Neste caso, podemos utilzar a função separate para dividí-la e criar duas novas colunas com seus dados separados.
table3 |>
separate(rate, sep = "/",
into = c("casos", "pop")) 2.5.0.3 separate_rows
Use para dividir cada célula de uma coluna em várias linhas.
É similar a função separate, porém o conteúdo de cada célula irá para uma linha ao invés de uma colunas.
table3 |>
separate_rows(rate, sep = "/") 2.6 Lidando com Valores Ausentes
Muitas vezes precisamos ignorar ou substituir valores ausentes (NA). Para isso, podemos usar as funções drop_na(), fill() ou replace_na()
2.6.0.1 drop_na
Ignora linhas que possuem valores ausentes (NA) nas colunas.
Por exemplo, na tabela starwars, temos 5 personagens que não possuim cor de cabelo (hair color):
starwars |>
select(name, hair_color) |>
filter(is.na(hair_color))Se pedirmos para listar todos os personagens e utilizarmos a função drop_na(), estes 5 personagens não serão listados:
starwars |>
select(name, hair_color) |>
drop_na()2.6.0.2 fill
Use para substituir o valores ausente (NA) da coluna pelo último valor disponível em linhas anteriores ou posteriores.
Por exemplo:
Como vimos no exemplo da função drop_na, temos 5 personagens de starwars que não possuem cor de cabelo preenchido.
Digamos que decidimos substituir estes NAs pelo cor de cabelo do personagem anterior disponível. Para isso, faremos:
starwars |>
select (name, hair_color) |>
fill(hair_color)Veja que o personagem C-3PO que tinha a cor de cabelo não preenchida, agora está como loiro (blond), pois o personagem anteriormente preenchido, era o Luke Skywalker, que tinha a cor de cabelo loiro (blond). Já o personagem R5-D4, teve sua cor de cabelo preenchida de marron (brown), pois o personagem anterior Beru Whitesun lars, tinha o cabelo marron (brown).
2.6.0.3 replace_na
Use para substituir os valores de NA por um valor específico.
Por exemplo, vamos substituir a cor de cabelo dos personagens que tem NA na coluna “hair_color” pela cor azul (blue).
starwars |>
select(name, hair_color) |>
replace_na(list(hair_color = "blue"))
Aviso
Veja que a função replace_na, recebe uma lista de valores (list()) se os dados passados no primeiro parâmetro é um data frame.
2.7 Dados Aninhados
2.7.1 Introdução
Um data frame aninhado (nested) é aquela que possui tabelas completas em colunas do tipo lista (colunas de lista) dentro de outro data frame maior e organizado. Uma coluna de lista, podem ser também listas de vetores ou listas de vários tipos de dados.
Alguns uso de um data frame de dados aninhados são:
Preservar o relacionamento entre observações e sub-grupos de dados.
Preservar o tipo da variável aninhada (factors e datetime não viram caracteres por exemplo).
Manipular várias sub-tabelas de uma vez com funcções do pacote purrr como map(), map2() ou pmap() ou com a rowwise() do pacote dplyr.
2.7.2 Criando dados Aninhados
2.7.2.1 nest
Use para mover grupos de células para uma coluna de lista de um data frame. Pode ser usada sozinha ou em conjunto com a grupo_by().
Exemplo 1: nest() com groupg_by()
Digamos que gostaríamos ter uma linha para cada furacão de nosso data frame (storms) e em uma coluna de lista, uma tabela dos dados do respectivo furação. Para isso, podemos utilizar a função nest() em conjunto com a função group_by(). Veja abaixo:
n_storms <- storms |>
group_by(name) |>
nest()
head(n_storms, 15)Observe que na coluna “data”, temos um objeto <tibble> para grupo criado pela função group_by. A função nest() aninhou todas as demais variáveis nestas pequenas tabelas para cada um deles e armazenou na coluna do tipo lista.
Para acessar a tibble gerada para o primeiro grupo (furacão “Amy” na primeira linha acima), podemos fazer:
n_storms$data[[1]] Para acessar todas as observações as variáveis “month” e “status” especificamente, podemos usar:
n_storms$data[[1]][, c("month", "status")] |>
head() Exemplo 2: nest() especificando colunas
Digamos que precisamos especfificar as colunas que gostaríamos de aninhar em cada linha da coluna de lista. Apenas para simplificar o exemplo, iremos selecionar com a função selct() apenas as colunas “name”, “year”, “lat” e “long”. Depois iremos aninhar as colunas “year” até a coluna “long” em um coluna de lista chamada “data”. Veja a seguir:
n_storms <- storms |>
select(name, year, lat, long) |>
nest(data = c(year:long))
head(n_storms)Agora temos as colunas “year”, “lat” e “long” aninhadas na coluna de lista chamada “data” para cada observação da coluna “name”.
Assim como vimos anteriormente, podemos acessar as tibbles da coluna dat usando [[ ]]. Por exemplo:
n_storms$data[[1]]2.7.3 Criando Tibbles com Colunas de Listas
Para criar um objeto tibble com colunas de lista (list-column), você pode utilizar as mesmas funções tibble(), trible() e enframe(), passando uma objeto lista para a coluna.
2.7.3.1 tibble
Use para criar uma tibble com uma coluna de lista salvando uma lista na coluna.
tibble(max=c(3,4,5), seq=list(1:3, 1:4, 1:5))2.7.3.2 tribble
Use para criar uma tibble com uma coluna de lista por linhas.
tribble(~max, ~seq,
3, 1:3,
4, 1:4,
5, 1:5)2.7.3.3 enframe
Use para converter listas em um tibble dentro de uma coluna de lista.
lista <- list('3'=1:3, '4'=1:4, '5'=1:5)
enframe(lista, 'max', 'seq')
Nota
Observe que nossa lista possui “nomes” nos vetores (3, 4 e 5), se isso não for o caso, ele irá nomear as colunas com a sequencia lógica dos vetores (1, 2 e 3).
2.7.3.4 Outras Funções Retornam Coluna de Lista
Algumas funções, como por exemplo, mutate(), transmute() e summarise() do pacote dplyr tem como saída uma colunas de lista caso retornem uma lista.
Por exemplo, se criarmos uma lista com os quartis da variável consumo (mpg) da tatela mtcars agrupada por cilindros (cyl) e utilzarmos a função summarise(), teremos uma coluna de lista contendo os quartis para cada grupo de cilindro.
mtcars |>
group_by(cyl) |>
summarise(q = list(quantile(mpg)))2.7.4 Reformatando dados Aninhados
2.7.4.1 unest
Use para desaninhar os dados. Esta função, faz o inverso da função nest.
Por exemplo, para desaninhar os dados da coluna data criada na tabela n_storms, fazemos:
n_storms |>
unnest(data)2.7.4.2 unest_longer
Use para desaninhar um coluna de lista, tornando cada elemento da lista em uma linha.
Por exemplo, na tabela starwars, temos uma coluna de lista chamada “films”, nesta coluna temos uma lista de filmes que cada personagem participou. Se quisermos desaninhar esta coluna e colocar cada filme em uma linha, faremos:
starwars |>
select(name, films) |>
unnest_longer(films)2.7.4.3 unest_wider
Use para desaninhar um coluna de lista, tornando cada elemento da lista em uma coluna.
Por exemplo, na tabela starwars, temos uma coluna de lista chamada “films”, nesta coluna temos uma lista de filmes que cada personagem participou. Se quisermos desaninhar esta coluna e colocar cada filme em uma coluna, faremos:
starwars |>
select(name, films) |>
unnest_wider(films, names_sep = '_')2.7.4.4 hoist
Use para selecionar componentes específicos de uma lista e desaninhá-lo em uma nova coluna. É similar ao unnest_wider(), mas desaninha colunas específicas usando a sintaxe do purrr:pluck().
Por exemplo, vamos desaninhar apenas o primeiro e segundo filmes em que o psernagem de starwars particiou e manter os demais anihados:
starwars %>%
select(name, films) %>%
hoist(films, "1o_filme" = 1, "2o_filme" = 2)2.7.5 Transfromando dados Aninhados
Uma função vetorizada recebe um vetor, transforma cada elemento em paralelo e retorna um vetor de mesmo tamanho que o vetor de entrada. Estas funções sozinhas não trabalham com listas, e consequentemente, não trabalham com colunas de listas.
A função dplyr::rownames() agrupa cada linha da tabela em um grupo diferente e dentro de cada grupo os elementos da coluna de lista aparecem diretamente (acessados por colchetes duplo) e não mais como uma lista e tamanho 1.
Portanto, quando usamos a rownames(), as funções vetorizadas do pacote dplyr poderão ser aplicadas em uma coluna de lista de uma forma vetorizada.
2.7.5.1 Exemplo 1:
Vamos aplicar a função mutate() para criar uma nova coluna de lista contendo as dimensões do tibble presente na coluna “data”:
n_storms |>
rowwise() |>
mutate ("dim" = list(dim(data)))2.7.5.2
Neste exemplo, utilzamos a função dim() que retorna as dimensões de um objeto. Como na coluna “data”, temos um objeto tibble para cada linha, a função dim irá retornar dois valores (qtd de linha e qtd de colunas).
Isto só funcionou porque agrupamento através da função rowwise() a tabela anterior.
2.7.5.3 Exemplo 2:
Vamos aplicar a função mutate() para criar um coluna “normal” contendo o número de linhas da tibble presente na coluna “data”:
n_storms |>
rowwise() |>
mutate ("num_linhas" = nrow(data))2.7.5.4 Exemplo 3:
Vamos aplicar a função mutate() para criar um coluna de lista contendo uma outra lista com a união entre as colunas de listas “vehicles” e “starships” presentes na tabela starwars:
starwars |>
rowwise() |>
mutate (transporte = list(append(vehicles, starships))) |>
select(name, transporte)
Dica
Se quisermos pegar os transportes criados e colocá-los em linhas, podemos usar a função unest.
starwars |>
rowwise() |>
mutate (transporte = list(append(vehicles, starships))) |>
select(name, transporte) |>
unnest(transporte)2.7.5.5 Exemplo 4:
Vamos aplicar a função mutate() para criar um coluna de lista contendo uma o tamanho das listas “vehicles” e “starships” presentes na tabela starwars, e depois iremos desaninhar esta lista, obtendo assim quantos transportes cada personagem possui:
starwars |>
rowwise() |>
mutate (transporte = list(length(c(vehicles, starships)))) |>
select(name, transporte) |>
unnest(transporte)
Dica
Veja o pacote purrr para outras funções que manipulam listas em Programação Funcional.
Observe pelos exemplos anteriores que quando temos uma função que retorna uma lista, devemos usar a função list() para criar uma coluna de lista. Se a função retorna um valor (ex um inteiro), a coluna criada será um coluna “normal”, neste caso um coluna de inteiros.
2.8 Bônus
2.8.1 Combinando dados com fuzzy
Apesar de não fazer parte da Folha de Resumo, iremos mostrar sobre algo que é bastante comum quando não temos dados exatamente iguais para fazermos as uniões de duas ou mais tabelas (joins).
Pense, por exemplo, que em um lado, temos nossa já conhecida tabela STARWARS, onde temos uma coluna chamada espécie (species). Agora imagine que você tem uma segunda tabela, chamada EXOPLANETS, onde tenhamos a localização do planeta em relação à terra e a principal espécie que habita este planeta. Agora, gostaríamos de juntar estas duas tabelas, para sabermos de qual planeta determinado personagem é originário.
Primeiro, vamos mostrar esta tabela fictícia:
exoplanets <- read_csv("exoplanets.csv")Agora, vamos tentar fazer uma combinação utilizando a função que já conhecemos left_join().
starwars |> select(name, species) |>
left_join(exoplanets, by = c("species" = "Especie"))Observe que no caso acima, as linhas onde a espécie é igual a “Droid” e “Mon Calamari” não foram encontradas. Isso ocorreu pois ,na tabela “exoplanets”, estes registros foram incorretamente cadastrados. Onde deveríamos ter o valor Droid, temos Droids e onde teveríamos ter a espécie Mon Calamari, temos Mon Calamare.
Nestes casos, a união exata não irá funcionar. Obviamente, podemos alterar manualmente os valores para que a união funcione. Quando esta possibilidade não existe, podemos utilziar uma lógica fuzzy através do pacote fuzzy_join. Este pacote possui uma série de funções que auxiliam a fazermos uniões não-exatas. Veja como ficaria o exemplo anterior utilizando a função stringdist_left_join:
library("fuzzyjoin")
x <- starwars |>
select(name, species) |>
filter(!is.na(species))
y <- drop_na(exoplanets)
stringdist_left_join(x= x,
y= y,
by = c("species" = "Especie"),
method = "lv",
max_dist = 1) |>
select(name, species, Especie, Planet, Distance) No exemplo acima, utilizamos a métrica de distância Levenshtein (lv), mas este pacote possui muitas outros algoritmos, como por exemplo (Jairo-Wilker (jw)). Para maiores informações digite ?fuzzyjoin