library (tidyverse)7 Programação Funcional com PURRR
7.1 Introdução
A seguir temos uma série de facildades que o pacote PURRR do R trás para trabalharmos com listas, funções e um paradigma de programação funcional.
Para saber mais sobre este pacote, acesse:
https://cran.r-project.org/package=purr.
Aviso
Para melhor utilizar este material, é importante que você tenha uma introdução à linguagem R e saiba carregar pacotes (packages) no R. Para mais informações acesse:
Para os exemplos, iremos carregar o seguinte pacote:
- tidyverse
7.1.1 Exemplos da Folha de Referência
A maioria dos exemplos, visam ajudar na interpretação dos exemplos e funções encontradas na Folha de Referência do purrr disponível no site do RStudio.


7.2 Programação Funcional
Programação funcional é um paradigma de programação onde aplicações são construídas aplicando uma composição de funções. É um paradigma de programação declarativa, onde definições de funções são árvores de expressão que mapeam um valor para outro valor, ao invés de comandos imperativos que mudam o estado do programa.
Para tentar deixar este tema mais simplificado, vamos imaginar um cenário bem simples on você já está familiarizado com algumas funções do R e decide começar a utilizá-lo. Após um certo tempo, chegará a conclusão que muitas vezes ao trabalhar com dados, precisamos utilizar a mesma função com alguns parêmtros diferentes para concluirmos nossa análise.
Dentro dessa ideia básica, digamos que precise da média e valor máximo da variável peso (wt) da base de dados mtcars:
mtcarsPara isso poderíamos fazer:
mean (mtcars$wt)[1] 3.21725sd (mtcars$wt)[1] 0.9784574Depois, você acaba precisando da média e valor áximo para outra variável, digmos potencia (hp) e depois para consumo (mpg).
mean (mtcars$hp)[1] 146.6875sd (mtcars$hp)[1] 68.56287mean (mtcars$mpg)[1] 20.09062sd (mtcars$mpg)[1] 6.026948Veja que com simples funções como estas de média (mean) e valor máximo (max), seu código já está ficando repetitivo e com várias replicações.
É exatamente para este e alguns outros desafios, que o pacote purr vem ajudar. Ele, entre outras coisas, ajuda na redução de linhas similares de código, aplicando funções à conjuntos de dados, diminuindo as replicações de código e o deixando com maior entendimento.
7.3 Mapeando funções
No pacote purrr, existem diversas funções que ajudam a mapear outras funções, onde ao receber uma, duas ou mais listas, iremos aplicar a mesma função para cada uma delas. Veremos à seguir como devemos proceder para estes cenários.
7.3.1 Uma lista
Seguindo o simples caso da média visto há pouco, poderíamos usar uma função de mapeamento (map) para aplicar as funções mean() e sd() para diversos items de uma lista e retornar um vetor de mesmo tamanho da lista. Nossa lista, pode conter o valor da variável wt, hp, mpg e muitas outras, mantendo-se com um código mais enxuto.
Então, em resumo, a função map, recebe uma lista de valores, aplica um função a ser definida e retorna uma lista com o mesmo tamanho da lista de entrada.
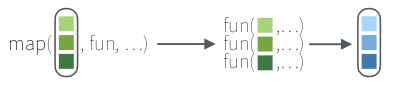
Veja como ficaria nosso exemplo das médias e valor máximo com a função map():
#Cria uma lista para a entrada
lista <- list("wt"=mtcars$wt, "hp"=mtcars$hp, "mpg"=mtcars$mpg)
#Cria um mapeamento da lista e a função que iremos executar para cada elemento da lista.
media <- map(lista, mean)
maximo <- map(lista, max)Veja que se precisarmos a fazer a média e valor máximo para 10 novas variáveis, precisamos apenas incluí-las na lista e nenhuma outra alteração no código seria necessária.
Agora podemos juntar ambas as listas em um data frame para uma melhor visualização:
bind_rows(media, maximo) |> mutate (tipo = c("media", "maximo"), .before = 1) #Esta linha é apenas para agrupar em um data frame e mostrar a saída. O mapeamento já ocorreu nas linhas anteriores.Espero que até aqui já dê para ter uma idéia do poder do uso de funções mapeadas. Iremos ver agora diversos “sabores” desta idéia para apenas uma lista de entrada.
Para os próximos exemplos, iremos usar duas listas:
Listas x e l1:
x <- list(1:10, 11:20, 21:30)
x[[1]]
[1] 1 2 3 4 5 6 7 8 9 10
[[2]]
[1] 11 12 13 14 15 16 17 18 19 20
[[3]]
[1] 21 22 23 24 25 26 27 28 29 30l1 <- list(x = c("a", "b"), y = c("c", "d"))
l1$x
[1] "a" "b"
$y
[1] "c" "d"7.3.1.1 map
Como já vimos, podemos usar esta função para aplicar uma função em cada elemento da lista ou vetor de entrada e retornar uma lista.
Vejamos outro exemplo, só que desta vez, vamos passar argumentos para função mapeada.
map(l1, sort, decreasing = TRUE)$x
[1] "b" "a"
$y
[1] "d" "c"Neste exemplo, aplicamos a função sort() para cada elemento da lista “l1”.
Passamos também o argumento decreasing = TRUE para a função sort().
Nota
Existem outras formas de declarar a função e passar os argumentos. Para maiores detalhes, veja a seção Atalhos para funções.
Podemos usar a função str() para ver a estrutura da lista. Veja:
str(l1)List of 2
$ x: chr [1:2] "a" "b"
$ y: chr [1:2] "c" "d"As funções a seguir, fazem praticamente a mesma coisa que a função map(), porém retornam, ao invés de uma lista, outro tipo de dado.
7.3.1.2 map_dbl
Use esta função para aplicar uma função em cada elemento da lista ou vetor de entrada e retornar um vetor de double.
map_dbl(x, mean)[1] 5.5 15.5 25.57.3.1.3 map_int
Use esta função para aplicar uma função em cada elemento da lista ou vetor de entrada e retornar um vetor de inteiro.
map_int(x,length)[1] 10 10 107.3.1.4 map_chr
Use esta função para aplicar uma função em cada elemento da lista ou vetor de entrada e retornar um vetor de caractere.
map_chr(l1, paste, collapse = "") x y
"ab" "cd" 7.3.1.5 map_lgl
Use esta função para aplicar uma função em cada elemento da lista ou vetor de entrada e retornar um vetor lógico.
map_lgl(x, is.integer)[1] TRUE TRUE TRUE7.3.1.6 map_dfc
Use esta função para aplicar uma função em cada elemento da lista ou vetor de entrada e retornar um dataframe juntando em colunas.
map_dfc(l1, rep, 3)Neste exemplo, aplicamos a função rep() para replicar em três vezes cada elemento da lista “l1” e retornar em um dataframe, juntando cada elemento em colunas.
7.3.1.7 map_dfr
Use esta função para aplicar uma função em cada elemento da lista ou vetor de entrada e retornar um dataframe juntando em linhas.
map_dfr(x, summary)7.3.1.8 walk
Use esta para executar uma atividade assim como a função map(), mas de forma silenciosa, ou seja, se houver mensagens de saída, elas não aparecerão. Ela também retorna a lista de entrada. Isto ajuda em situações com o pipe.
walk(x, print) [1] 1 2 3 4 5 6 7 8 9 10
[1] 11 12 13 14 15 16 17 18 19 20
[1] 21 22 23 24 25 26 27 28 29 307.3.2 Duas listas
O pacote purr tem um conjunto de funções similares ao map(), porém, ao invés de receber apenas uma única lista de entrada e retornar um vetor de mesmo tamanho, elas aceitam duas listas de entrada e retornam também um vetor de mesmo tamanho na saída.
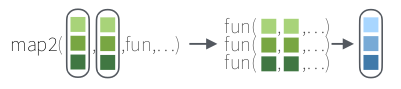
Vamos criar nossas listas para os próximos exemplos:
Listas y, z e l2:
y <- list(1, 2, 3)
z <- list(4, 5, 6)
l2 <- list(x = "a", y = "z")7.3.2.1 map2
Use para aplicar uma função em um par de listas e retornar uma lista.
map2(x,y,rep)[[1]]
[1] 1 2 3 4 5 6 7 8 9 10
[[2]]
[1] 11 12 13 14 15 16 17 18 19 20 11 12 13 14 15 16 17 18 19 20
[[3]]
[1] 21 22 23 24 25 26 27 28 29 30 21 22 23 24 25 26 27 28 29 30 21 22 23 24 25
[26] 26 27 28 29 30Veja que neste exemplo, para cada elemento da lista “x”, aplicamos a função rep() para replicar em número de vezes cada elemento da lista “y”.
O purr possui uma sintaxe, onde ao invés de termos explicitamente o nome de uma função, podemos criá-la no momento do mapeamento. Para maiores detalhes veja Atalhos para funções.
map2(x,y, ~ .x*.y)[[1]]
[1] 1 2 3 4 5 6 7 8 9 10
[[2]]
[1] 22 24 26 28 30 32 34 36 38 40
[[3]]
[1] 63 66 69 72 75 78 81 84 87 90Ao invés de usarmos uma função que multiplicasse dois números, simplesmente declaramos uma função com o “~” e depois informamos o que esta função fará, neste caso, irá multiplicar “*” os elementos da lista “x” pelos da lista “y”.
7.3.2.2 map2_dbl
Use para aplicar uma função em um par de listas e retornar um vetor double.
map2_dbl(y, z, ~ .x / .y)[1] 0.25 0.40 0.507.3.2.3 map2_int
Use para aplicar uma função em um par de listas e retornar um vetor de inteiros.
map2_int(as.integer(y), as.integer(z), `+`)[1] 5 7 97.3.2.4 map2_chr
Use para aplicar uma função em um par de listas e retornar um vetor de caracteres.
map2_chr(l1, l2, paste, collapse = ",", sep = ":") x y
"a:a,b:a" "c:z,d:z" 7.3.2.5 map2_lgl
Use para aplicar uma função em um par de listas e retornar um vetor lógico.
map2_lgl(l2, l1, `%in%`) x y
TRUE FALSE 7.3.2.6 map2_dfc
Use para aplicar uma função em um par de listas e retornar um data frame agrupado por colunas.
map2_dfc(l1, l2,~ as.data.frame(c(.x, .y)))7.3.2.7 map2_dfr
Use para aplicar uma função em um par de listas e retornar um data frame agrupado por linhas.
map2_dfr(l1, l2,~ as.data.frame(c(.x, .y)))7.3.2.8 walk2
Use esta para executar uma atividade assim como a função map2(), mas de forma silenciosa, ou seja, se houver mensagens de saída, elas não aparecerão. Ela também retorna a primeira lista de entrada. Isto ajuda em situações com o pipe ou por exemplo, quando precisamos salvar multiplos arquivos mas não queremos as mensagens de saída em nosso processo.
walk2(l1,l2, ~c(.x,.y))7.3.3 Várias listas
O pacote purr tem um conjunto de funções similares ao map(), porém, ao invés de receber apenas uma única lista de entrada e retornar um vetor de mesmo tamanho, elas aceitam uma lista com outras listas ou vetores (com um data frame) e retornam também um vetor de mesmo tamanho na saída.

Vejamos as princpais funções deste tipo:
7.3.3.1 pmap
Diagmos que temos três listas (x,y e z) e precisamos aplicar uma função à elas. Neste caso,
pmap(list(x,y,z), sum)[[1]]
[1] 60
[[2]]
[1] 162
[[3]]
[1] 264Assim como explicado com as funções map() e map2(), temos as variantes abaixo seguindo a mesma nomenclatura para pmap, sendo que cada uma delas retornam os respectivo tipo após o _ . Por exemplo, a pmap_dbl() funciona similar ao pmap(), porém retorna uma lista de vetores double e assim por diante.
pmap_dbl
pmap_int
pmap_chr
pmap_lgl
pmap_dfc
pmap_dfr
pwalk
7.3.4 Listas e índices
O pacote purr tem um conjunto de funções similares ao map(), porém, ao invés de receber apenas uma única lista de entrada e retornar um vetor de mesmo tamanho, elas aplicam uma função para cada elemento e seu índice.
Usamos o símbolo ~ para declarar uma fórmula, .x para acessar os valores dos elementos e .y para acessar o índice do elemento.
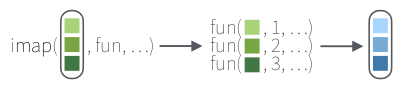
7.3.4.1 imap
imap(y, ~paste0(.y, ": ", .x))[[1]]
[1] "1: 1"
[[2]]
[1] "2: 2"
[[3]]
[1] "3: 3"Assim como explicado com as funções map() e map2(), temos as variantes abaixo seguindo a mesma nomenclatura para imap, sendo que cada uma delas retornam os respectivos tipo após o _ .
Por exemplo, a imap_dbl() funciona similar ao imap(), porém retorna uma lista de vetores double e assim por diante.
imap_dbl
imap_int
imap_chr
imap_lgl
imap_dfc
imap_dfr
iwalk
7.4 Atalhos para funções
Até o momento, na maioria dos casos, declaramos o nome da função durante o processo de mapeamento, mas o pacote purr possui alguns atalhos para faciliar este processo. Também não mencionamos, mas as funções vistas até aqui, não aceitam apenas funções, mas também fórmulas ou vetores.
Temos atalhos de funções para cenários de uma, duas, várias e listas e índices.
- Atalho para Uma Lista, por exemplo, usando map() ou suas derivações:
Use ~. para passar um argumento para a função:
map(y, ~.+2)[[1]]
[1] 3
[[2]]
[1] 4
[[3]]
[1] 5O atalho acima, é o mesmo que declararmos uma função x por exemplo:
map(y,function(x) x+2)[[1]]
[1] 3
[[2]]
[1] 4
[[3]]
[1] 5Apenas para ilustrar as possibildades, digamos que precisemos encurtar os nomes dos filmes de starwars que cada personagem participou. Para isto podemos fazer algo como:
sw_trunc <-
map(starwars$films, ~str_trunc(., width=15, side="right")) |>
set_names(starwars$name)
sw_trunc[1:3]$`Luke Skywalker`
[1] "The Empire S..." "Revenge of t..." "Return of th..." "A New Hope"
[5] "The Force Aw..."
$`C-3PO`
[1] "The Empire S..." "Attack of th..." "The Phantom ..." "Revenge of t..."
[5] "Return of th..." "A New Hope"
$`R2-D2`
[1] "The Empire S..." "Attack of th..." "The Phantom ..." "Revenge of t..."
[5] "Return of th..." "A New Hope" "The Force Aw..."- Atalho para Duas Listas, por exemplo, usando map2() ou suas derivações:
Use ~.x.y para passar dois argumentos:
map2(y,z,~.x+.y)[[1]]
[1] 5
[[2]]
[1] 7
[[3]]
[1] 9O atalho acima, seria o mesmo que declararmos uma função passando dois argumentos como:
map2(y,z,function(a,b) a+b)[[1]]
[1] 5
[[2]]
[1] 7
[[3]]
[1] 9- Atalho para Várias Listas, por exemplo, usando pmap() ou suas derivações:
Use ~..1 ..2 ..3 etc para passar multiplos argumentos para a função sem declará-la:
pmap(list(x,y,z), ~..3 + ..1 - ..2)[[1]]
[1] 4 5 6 7 8 9 10 11 12 13
[[2]]
[1] 14 15 16 17 18 19 20 21 22 23
[[3]]
[1] 24 25 26 27 28 29 30 31 32 33O atalho acima, seria o mesmo que declararmos uma função com três argumentos
pmap(list(x,y,z), function(a,b,c) c+a-b)[[1]]
[1] 4 5 6 7 8 9 10 11 12 13
[[2]]
[1] 14 15 16 17 18 19 20 21 22 23
[[3]]
[1] 24 25 26 27 28 29 30 31 32 33- Atalho para Listas e Índices, por exemplo, usando imap() ou suas derivações:
Use ~ .x .y , sendo que .x retorna o valor da lista e .y o valor do índice.
imap(list(x, y, z), ~paste0(.y, ": ", .x))[[1]]
[1] "1: 1:10" "1: 11:20" "1: 21:30"
[[2]]
[1] "2: 1" "2: 2" "2: 3"
[[3]]
[1] "3: 4" "3: 5" "3: 6"O atalho acima, retornou <índice>:<valor>
7.5 Acessando os elementos
Podemos usar uma string ou um inteiro com qualquer função map para indexar elementos das listas por nome ou posição.
Vejamos um exemplo. Para obter o segundo valor de cada elemento na lista “l1”, podemos usar
map(l1, 2)$x
[1] "b"
$y
[1] "d"O código acima, seria o mesmo que escrever:
map(l1, function(x)x[[2]])$x
[1] "b"
$y
[1] "d"7.6 Trabalhando com Listas
Como vimos na função map(), map2(), pmap(), imap(), a estrutura de lista é essencial, pois é a entrada e saída destas funções, por isso, o pacote purr possui diversas funções que permitem manipular listas, com filtrar, remodelar, combinar, modificar e reduzí-las. Veremos a seguir diversas destas funções.
7.6.1 Filtros
7.6.1.1 keep
Use para manter os elementos que passam em um teste lógico. Por exemplo, em nossa lista “x”, temos 3 elementos.
x[[1]]
[1] 1 2 3 4 5 6 7 8 9 10
[[2]]
[1] 11 12 13 14 15 16 17 18 19 20
[[3]]
[1] 21 22 23 24 25 26 27 28 29 30Digamos que precisamos manter na lista, apenas os vetores que tem a o valor máximo maior que 15. Para isso, podemos fazer:
keep (x, function(x) max(x)>15)[[1]]
[1] 11 12 13 14 15 16 17 18 19 20
[[2]]
[1] 21 22 23 24 25 26 27 28 29 30Veja que apenas os dois últimos elementos de “x” passaram pelo teste (max >15) e por isso, foram retornados pela função.
Se quiser fazer o oposto, ou seja, ao invés de retornar os items que passaram pelo teste, manter os que não passaram, podemos usar a função discard().
discard (x, function(x) max(x)>15)[[1]]
[1] 1 2 3 4 5 6 7 8 9 10Se usarmos o atalho para função como visto anteriormente, poderíamos reescrever o código anteior como:
discard (x, ~max(.)>15)[[1]]
[1] 1 2 3 4 5 6 7 8 9 107.6.1.2 compact
Use para excluir elementos em branco. Por exemplo, digamos que temos uma lista “x_na” que possui 7 elementos, sendo que quarto é nulo:
x_nulo <- splice(x, NULL, y)
x_nulo[[1]]
[1] 1 2 3 4 5 6 7 8 9 10
[[2]]
[1] 11 12 13 14 15 16 17 18 19 20
[[3]]
[1] 21 22 23 24 25 26 27 28 29 30
[[4]]
NULL
[[5]]
[1] 1
[[6]]
[1] 2
[[7]]
[1] 3Usando a função compact() iremos remover os elementos ausentes:
compact(x_nulo)[[1]]
[1] 1 2 3 4 5 6 7 8 9 10
[[2]]
[1] 11 12 13 14 15 16 17 18 19 20
[[3]]
[1] 21 22 23 24 25 26 27 28 29 30
[[4]]
[1] 1
[[5]]
[1] 2
[[6]]
[1] 37.6.1.3 head_while
Use para retornar os elementos do topo da lista, até encontrar o primeiro que não passa no teste lógico. No exemplo a seguir, iremos obter os valores do topo da lista até que um valor não passe no teste lógico, neste caso, não passe no teste de não ser numérico. Portanto, ao encontrar o elemento nulo, ele irá passar e retornar os elementos do topo encontrados até o momento.
head_while(x_nulo, function (x) is.numeric(x))[[1]]
[1] 1 2 3 4 5 6 7 8 9 10
[[2]]
[1] 11 12 13 14 15 16 17 18 19 20
[[3]]
[1] 21 22 23 24 25 26 27 28 29 30Para fazer o mesmo processo, porém pegar os elementos do fim da lista, ao invés do topo use a função tail_while(). Por exemplo, quando precisamos obter os elementos do fim da lista, até encontrarmos um valor que não tenho mais que 1 caractere.
tail_while(x_nulo, ~length(.<2))[[1]]
[1] 1
[[2]]
[1] 2
[[3]]
[1] 37.6.1.4 detect
Use para encontrar o primeiro elemento que passa no teste lógico. Usamos os argumentos “dir=” para definir se queremos buscar do início da lista até o fim (forward) (padrão) ou o inverso (backward). No exemplo a seguir, iremos encontrar o elemento que tem o valor máximo menor que 15, mas varrendo a lista de baixo para cima:
detect (x_nulo, ~max(.)<15, dir="backward") [1] 1 2 3 4 5 6 7 8 9 10
Dica
Se quisermos obter o índice do elemento ao invés dos valores do elemento, podemos usar a função detect_index()
detect_index(x_nulo, ~max(.)<15)[1] 17.6.1.5 every
Use para verificar se todos os elementos da lista passam no teste lógico.
every(x_nulo, ~max(.)<15)[1] FALSE7.6.1.6 some
Use para verificar se algum elemento da lista passam no teste lógico.
some(x_nulo, ~max(.)<15)[1] TRUE7.6.1.7 none
Use para verificar se nenhum elemento da lista passam no teste lógico.
none(x_nulo, ~max(.)<15)[1] FALSE7.6.1.8 has_element
Use para verificar se uma lista tem determinado elemento.
elemento <- 2
has_element(x_nulo, elemento)[1] TRUE7.6.1.9 vec_depth
Use para obter a profundidade (número de níveis dos índices) de uma lista. Para exemplificar melhor, vamos criar uma lista com outras listas dentro:
#Criamos uma lista "lista_profunda" que tem como primeiro elemento a lista "x" e como segundo elemento a lista "y".
lista_profunda <- list(x, y)
vec_depth(lista_profunda)[1] 3# Se adicionarmos uma outra lista na lista "x", teremos um nível a mais:
x_com_sublista <- append(x, list(list(1:5)))
lista_mais_profunda <- list(x_com_sublista, y)
vec_depth(lista_mais_profunda)[1] 4
Nota
Temos sempre nível + 1, pois ele conta o nível 0 que é da própria lista.
7.6.2 Índices
O pacote purr tem uma série de funções para identificar elementos de uma lista, definí-los e/ou alterá-los por este índice. Vejamos algumas:
7.6.2.1 pluck
Use para selecionar um elemento por nome ou índice.
pluck(x, 2) [1] 11 12 13 14 15 16 17 18 19 20Neste caso, usamos a função pluck para obter o elemento no índice 2. Vamos agora dar nome aos elementos da lista “x”, usando a função set_names() do purr e depois obter o memos elemento por nome:
x <- set_names(x, c("a", "b", "c"))
pluck(x, "b") [1] 11 12 13 14 15 16 17 18 19 207.6.2.2 assign_in
Use para definir um valor ao elemento de acordo como a seleção feita na função pluck()
assign_in(x, "b", 5)$a
[1] 1 2 3 4 5 6 7 8 9 10
$b
[1] 5
$c
[1] 21 22 23 24 25 26 27 28 29 307.6.2.3 modify_in
Use para aplicar uma função de modificação nos valores do elemento selecionado como na função pluck().
modify_in(x, "b", log)$a
[1] 1 2 3 4 5 6 7 8 9 10
$b
[1] 2.397895 2.484907 2.564949 2.639057 2.708050 2.772589 2.833213 2.890372
[9] 2.944439 2.995732
$c
[1] 21 22 23 24 25 26 27 28 29 307.6.3 Remodelagem
O pacote purr possui uma série de funções para remodelar a forma de uma lista. Vejamos algumas delas:
7.6.3.1 flatten
Use para remover um nível de índice (profundidade) de uma lista. Ver também a função vec_depth para obter o número de profundidade de uma lista.
flatten (lista_profunda)[[1]]
[1] 1 2 3 4 5 6 7 8 9 10
[[2]]
[1] 11 12 13 14 15 16 17 18 19 20
[[3]]
[1] 21 22 23 24 25 26 27 28 29 30
[[4]]
[1] 1
[[5]]
[1] 2
[[6]]
[1] 37.6.3.2 array_tree
Use para transformar um array (estrutura de uma ou mais dimensão que contém o mesmo tipo de dados) em uma lista. É útil para permitir ouso de arrays em funções com as do purr, que aceitam listas.
meu_array <- array(1:3, c(2,4))
array_tree(meu_array)[[1]]
[[1]][[1]]
[1] 1
[[1]][[2]]
[1] 3
[[1]][[3]]
[1] 2
[[1]][[4]]
[1] 1
[[2]]
[[2]][[1]]
[1] 2
[[2]][[2]]
[1] 1
[[2]][[3]]
[1] 3
[[2]][[4]]
[1] 27.6.3.3 cross2
Use para gerar as combinações possíveis entre os elementos duas listas. Neste caso, iremos gerar um elemento de saída com o primeiro elemento de x e o primeiro de y. Depois iremos ter o segundo elemento contendo o primeiro elemento de x e segundo de y e assim por diante.
cross2 (x,y)[[1]]
[[1]][[1]]
[1] 1 2 3 4 5 6 7 8 9 10
[[1]][[2]]
[1] 1
[[2]]
[[2]][[1]]
[1] 11 12 13 14 15 16 17 18 19 20
[[2]][[2]]
[1] 1
[[3]]
[[3]][[1]]
[1] 21 22 23 24 25 26 27 28 29 30
[[3]][[2]]
[1] 1
[[4]]
[[4]][[1]]
[1] 1 2 3 4 5 6 7 8 9 10
[[4]][[2]]
[1] 2
[[5]]
[[5]][[1]]
[1] 11 12 13 14 15 16 17 18 19 20
[[5]][[2]]
[1] 2
[[6]]
[[6]][[1]]
[1] 21 22 23 24 25 26 27 28 29 30
[[6]][[2]]
[1] 2
[[7]]
[[7]][[1]]
[1] 1 2 3 4 5 6 7 8 9 10
[[7]][[2]]
[1] 3
[[8]]
[[8]][[1]]
[1] 11 12 13 14 15 16 17 18 19 20
[[8]][[2]]
[1] 3
[[9]]
[[9]][[1]]
[1] 21 22 23 24 25 26 27 28 29 30
[[9]][[2]]
[1] 3
Dica
Para combinar três listas usando a função cross3(). Para mais listas, usamos a função cross_df().
7.6.3.4 transpose
Use para transpor (mudar de linhas para colunas) a ordem dos índices em uma lista muti-nível:
transpose(lista_profunda)[[1]]
[[1]][[1]]
[1] 1 2 3 4 5 6 7 8 9 10
[[1]][[2]]
[1] 1
[[2]]
[[2]][[1]]
[1] 11 12 13 14 15 16 17 18 19 20
[[2]][[2]]
[1] 2
[[3]]
[[3]][[1]]
[1] 21 22 23 24 25 26 27 28 29 30
[[3]][[2]]
[1] 37.6.3.5 set_names
Use para definir nomes de um vetor/lista diretamente ou atraveś de uma função:
y <- set_names (y, c("a", "b", "c"))
y$a
[1] 1
$b
[1] 2
$c
[1] 3set_names(y, letters[4:6])$d
[1] 1
$e
[1] 2
$f
[1] 3set_names(y, toupper)$A
[1] 1
$B
[1] 2
$C
[1] 37.6.4 Modificações
O pacote purr possui uma série de funções para modificar elementos de uma lista. Vejamos algumas delas:
7.6.4.1 modify
Use para aplicar uma função à cada elemento de uma lista. Ela é similar à função map(), porém, diferente do map() que retorna uma lista ou um tipo específico quando utilizamos suas variantes (map_dbl, map_int, etc), a função modify retorna sempre o tipo do bjeto recebido (uma lista ou um vetor atômico).
Por exemplo, ao passar uma lista para a função, assim como a função map(), elá irá aplicar uma função ou fórmula e retornará uma lista de mesmo tamanho:
modify(x, ~.+2)$a
[1] 3 4 5 6 7 8 9 10 11 12
$b
[1] 13 14 15 16 17 18 19 20 21 22
$c
[1] 23 24 25 26 27 28 29 30 31 32Se passarmos um vetor de inteiros, ela aplicará uma função e retornará um vetor de mesmo tamanho de inteiros:
modify (mtcars$wt, ~.-2) [1] 0.620 0.875 0.320 1.215 1.440 1.460 1.570 1.190 1.150 1.440
[11] 1.440 2.070 1.730 1.780 3.250 3.424 3.345 0.200 -0.385 -0.165
[21] 0.465 1.520 1.435 1.840 1.845 -0.065 0.140 -0.487 1.170 0.770
[31] 1.570 0.7807.6.4.2 modify_at
Use para modificar um elemento definido por seu índice ou nome.
modify_at(x, "b", ~.*-1)$a
[1] 1 2 3 4 5 6 7 8 9 10
$b
[1] -11 -12 -13 -14 -15 -16 -17 -18 -19 -20
$c
[1] 21 22 23 24 25 26 27 28 29 307.6.4.3 modify_if
Use para modificar o(s) elemento(s) que passam por um teste lógico. Neste exemplo, iremos definir uma fórmula que testa se o valor máximo de um elemento é maior que 15. Para todos os elementos que passarem neste teste, iremos multiplicá-los por -1.
modify_if(x, ~max(.)>15, ~.*-1)$a
[1] 1 2 3 4 5 6 7 8 9 10
$b
[1] -11 -12 -13 -14 -15 -16 -17 -18 -19 -20
$c
[1] -21 -22 -23 -24 -25 -26 -27 -28 -29 -307.6.4.4 modify_depth
Use para aplicar uma função a cada elemento de uma lista que está à uma certa profundidade (certo nível). Em geral, utilizamos quando temos listas aninhadas (com outras listas dentro).
No exemplo abaixo, iremos retornar o maior valor, mas somente do terceiro nível da lista. Como temos apenas um elemento neste nível (lista_mais_profunda[[1]][[4]]), apenas este será usado para obter o maior valor atraveś da função max().
modify_depth(lista_mais_profunda, 3, ~max(.))[[1]]
[[1]][[1]]
[1] 1 2 3 4 5 6 7 8 9 10
[[1]][[2]]
[1] 11 12 13 14 15 16 17 18 19 20
[[1]][[3]]
[1] 21 22 23 24 25 26 27 28 29 30
[[1]][[4]]
[[1]][[4]][[1]]
[1] 5
[[2]]
[[2]][[1]]
[1] 1
[[2]][[2]]
[1] 2
[[2]][[3]]
[1] 3
Nota
A função map() tem variações como map_at() e map_if() que fazem o mesmo que as modify_at ou modify_if, porém retornando lista.
7.6.5 Combinações
O pacote purr possui uma série de funções para combinar elementos de diversas listas. Vejamos algumas delas:
7.6.5.1 append
Use para adicionar valores ao final de uma lista.
append (x, list(seq(55:60),66,c("aaa", "zzz")))$a
[1] 1 2 3 4 5 6 7 8 9 10
$b
[1] 11 12 13 14 15 16 17 18 19 20
$c
[1] 21 22 23 24 25 26 27 28 29 30
[[4]]
[1] 1 2 3 4 5 6
[[5]]
[1] 66
[[6]]
[1] "aaa" "zzz"
Dica
Use o argumento after= para especificar o índice a partir de onde os valores serão adicionados.
7.6.5.2 prepend
Use para adicionar valores ao começo da lista.
prepend(x , list(d = 1))$d
[1] 1
$a
[1] 1 2 3 4 5 6 7 8 9 10
$b
[1] 11 12 13 14 15 16 17 18 19 20
$c
[1] 21 22 23 24 25 26 27 28 29 30
Dica
Use o argumento before= para determinar o índice ao qual iremos adicionar os valores antes.
7.6.5.3 splice
Use para combinar objetos em uma lista única.
splice (x, "nova", c("a", "b"), list(seq(100:110)))$a
[1] 1 2 3 4 5 6 7 8 9 10
$b
[1] 11 12 13 14 15 16 17 18 19 20
$c
[1] 21 22 23 24 25 26 27 28 29 30
[[4]]
[1] "nova"
[[5]]
[1] "a" "b"
[[6]]
[1] 1 2 3 4 5 6 7 8 9 10 117.6.6 Reduções
O pacote purr tem uma algumas funções para reduzir uma lista aplicado funções de forma recursivas. Vejamos algumas:
7.6.6.1 reduce
Use para reduzir uma lista em um único valor, aplicando uma função binária. Uma função binária, recebe dois valores e retorna apenas um valor.
Por exemplo, utilziando nossa lista “x”, iremos reduzí-la a um única valor, pegando o valor do primeiro e segundo elementos, pegando seu retorno, aplicando a mesma função com este resultado e o terceiro elemento, e assim por diante;
# func(a,b) -- res1 --> func(res1, c) -- res_final
x$a
[1] 1 2 3 4 5 6 7 8 9 10
$b
[1] 11 12 13 14 15 16 17 18 19 20
$c
[1] 21 22 23 24 25 26 27 28 29 30reduce (x, sum)[1] 4657.6.6.2 reduce2
Use para reduzir uma lista em um único valor, aplicando uma função ternária, ou seja, receber duas listas ou vertores e aplica uma função que recebe três argumentos de forma recursiva.
Para este exemplo iremos criar uma função ternãria chamada paste2. Esta função simplesmente recebe três argumentos, concatena usando a função paste e retorna uma valor.
paste2 <- function(x, y, sep = ".") paste(x, y, sep = sep)Através da função reduce2, podemos aplicar nossa função paste2 e fazermos sua aplicação de forma recursiva através das duas listas de entrada “x” e “y”.
Importante
A segunda lista ou vetor de entrada (.y) deve ter um elemento a menos que o primeiro vertor (.x)
reduce2 (x, c("-", "--"), paste2) [1] "1-11--21" "2-12--22" "3-13--23" "4-14--24" "5-15--25" "6-16--26"
[7] "7-17--27" "8-18--28" "9-19--29" "10-20--30"7.6.6.3 accumulate
É similar a função reduce(), porém ela mostra o resultado de cada iteração.
x$a
[1] 1 2 3 4 5 6 7 8 9 10
$b
[1] 11 12 13 14 15 16 17 18 19 20
$c
[1] 21 22 23 24 25 26 27 28 29 30accumulate (x, sum)$a
[1] 1 2 3 4 5 6 7 8 9 10
$b
[1] 210
$c
[1] 4657.6.6.4 accumulate2
accumulate2 (x, c("-", "--"), paste2)[[1]]
[1] 1 2 3 4 5 6 7 8 9 10
[[2]]
[1] "1-11" "2-12" "3-13" "4-14" "5-15" "6-16" "7-17" "8-18" "9-19"
[10] "10-20"
[[3]]
[1] "1-11--21" "2-12--22" "3-13--23" "4-14--24" "5-15--25" "6-16--26"
[7] "7-17--27" "8-18--28" "9-19--29" "10-20--30"É similar a função reduce2(), porém ela mostra o resultado de cada iteração.
7.6.7 Colunas de Lista
Colunas de listas, são colunas em um data frame onde cada elemento é uma lista ou vetor ao invés de um vetor atômico (coluna tipo inteiro ou caractere, por exemplo).
Para maior detalhes sobre este tema, veja na seção sobre o pacote TIDYR:
../Organizacao/Organizacao_de_dados_com_tidyr.html#dados-aninhados
Manipulamos colunas de listas como uma coluna qualquer usando funções dso pacotes dplyr como mutate() ou transmute().
Usamos função do purr como map() para manipular os elementos dentro de cada lista da coluna.
Como cada elemento retornado pelas principais funções do purr como map(), map2() e pmap(), é uma lista, ao criar uma nova coluna em um data frame, ela será uma coluna do tipo lista.
Vejamos alguns exemplos:
sw_ship <-
starwars |>
transmute(name = name,
ships = map2(vehicles, starships, append))
sw_shipNeste exemplo, usamos a função append() para juntar duas listas e aplicamos esta função a cada elemento destas listas através da função map(). O retorno desta iteração é uma lista que será colocada em uma nova coluna da tabela chamada “ships” contendo todos os transportes de cada personagem.
Podemos usar a função unnest() do pacote tidyr para extrair os veículos (elementos da coluna de lista) de cada personagem.
sw_ship |> unnest(ships)Usando as funções derivadas de map() como map_int() e map_chr() retornar um vetor atômico e consequentemente a coluna a ser criada em um dataframe já será deste mesmo tipo. Veja um exemplo:
starwars |>
transmute (name = name,
n_filmes = map_int(films, length))Neste caso, a coluna “n_filmes” já é do tipo inteiro, pois a função map_int já retorna um vertor deste tipo. Neste exemplo, usamos a função length para obter o tamanho de cada vetor e usamos a map_int para iterar por toda a coluna de lista “films”, obtendo o número de filmes que cad personagem participou.