Mostrar código-fonte
library(tidyverse)
library(janitor)
library(nortest)
library(DataExplorer)
library(ggrepel)
library (plotly)
library(MASS)
library(rgl)
library(car)
library(nlme)
library(jtools)
library(questionr)
library(nnet)library(tidyverse)
library(janitor)
library(nortest)
library(DataExplorer)
library(ggrepel)
library (plotly)
library(MASS)
library(rgl)
library(car)
library(nlme)
library(jtools)
library(questionr)
library(nnet)Diferente do que vimos no artigo sobre Regressão Linear onde criamos um modelo de ML supervisionado para fazer inferências sobre uma variável dependente contínua, neste artigo iremos criar modelos onde a variável dependente obedece à uma distribuição de Bernoulli. Neste caso, temos uma variável dependente dicotômica (0 ou 1), tendo a probabilidade de um evento ocorrer (p) e dele não ocorrer (1-p). Este tipo de modelo, faz parte dos Modelos Lineares Generalizados (Generalized Linear Models), onde temos uma função de ligação canônica (link function) para mapear uma relação não linear em uma parte linear. Podemos dizer que é uma generalização do modelo de regressão simples, que permite, através desta função de ligação canônica, fazermos predições para outros tipos de distribuições diferentes da normal (ex, poisson, exponencial, binomial negativa, etc).
Para os próximos exemplos iremos utilizar a base de dados TitanicSurvival que possui informações sobre 1309 passageiros do navio Titanic. Usaremos a variável survived como variável dependente e as variáveis sexo, idade e classe como variáveis explicativas.
# Selecionar base TitanicSurvival
df <- TitanicSurvival |> as_tibble()
dfVeja que temos variáveis qualitativas tanto para a explicativa quanto para a variavel dependente. Devemos portanto, ou criar as variáveis dummies conforme vimos no artigo de Regressao Linear, seja de forma manual ou saber exatamente como as funçoes lidam com tais cenários.
Para nossos experimentos, iremos selecionar como variável dependente a survived que indica se a pessoa sobreviveu ou não à tragédia do navio Titanic. Ou seja, iremos criar modelo preditivo que, com base em variáveis explicativas presentes (sexo, idade e classe do passageiro) em nossa amostra de dados, tentemos prever se uma pessoa sobreviveria ou não.
flowchart LR A[Sex] --> B((Survived?)) C[Age] --> B((Survived?)) D[Passenger Class] --> B((Survived?))
Por se tratar de uma variável qualitativa, não temos média, mediana ou outras estatísticas desta natureza. Desta forma, iremos apenas criar um tabela de frequência (absoluta e relativa):
#Frequencia absoluta e relativa:
as_tibble(table(df$survived),
.name_repair = "unique") |>
bind_cols(
enframe(prop.table(
table(df$survived)))
) |> dplyr::select(sobreviventes = name, freq_absoluta = n, freq_relativa=value) |>
mutate (freq_relativa = scales::percent(as.numeric(freq_relativa)))Aqui, apenas a tabela em forma gráfica. Vemos que apenas 38% das pessoas sobreviveram.
df <- TitanicSurvival
df |> ggplot(aes(survived, fill = survived)) +
geom_bar() +
geom_label(stat = "count",
aes(label=
paste(..count.., "\n",scales::percent(after_stat(count/sum(count))))),
show.legend = F,
position = position_nudge(y=-20))+
theme_minimal()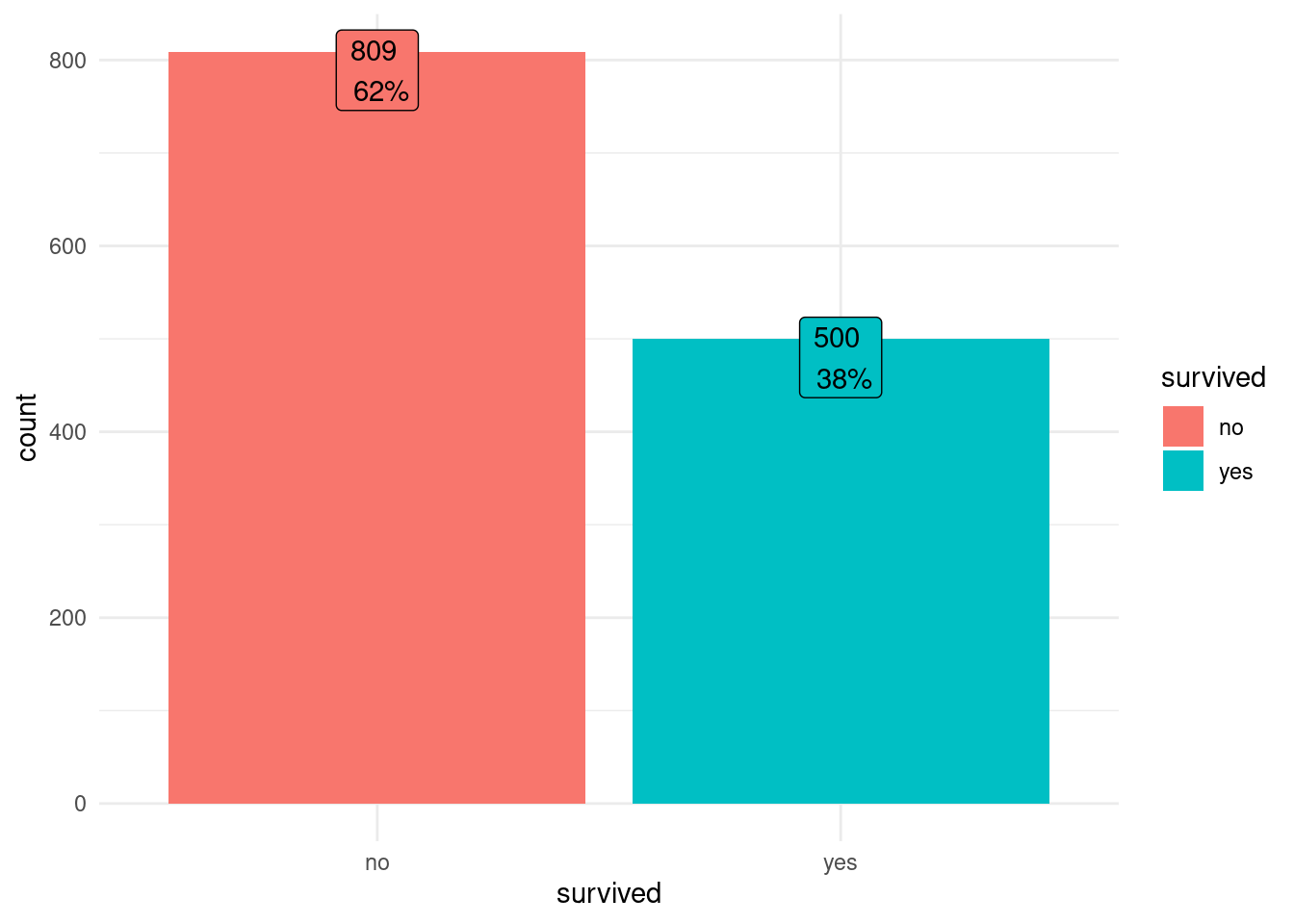
Diferente da regressão linear, onde a saída era um valor quantitativo definido pelas variáveis preditoras e respectivos parâmetros calculados para minimizar os erros do modelo, na regressão logística binomial, iremos calcular a probabilidade (p) do evento ocorrer ou não ocorrer com base no comportamente das variáveis preditoras. Ou seja, a variável dependente será categórica e dicotômica (zero ou um).
Se definirmos um vetor Z com as variáveis explicativas como:
Z_i = \alpha + \beta_1 * X_1 + \beta_2 * X_{2} + \beta_k * X_{k}
Z é conhecido como logito e não representa a variável dependente prevista (\hat{y}) como em um modelo de regressão linear simples, mas sim equivale ao logaritmo natural (ln) da chance (log odds).
Apesar de usarmos no mesmo sentido de probabilidade, Chance (odds) é um conceito estatístico definido pela razão do evento ocorrer e do evento não ocorrer. Chance e Probabildade NÃO são a mesma coisa.
chance (odds)_{Y_i=1} = \dfrac{p_i}{1 - p_i}
Já que nosso objetivo é calcular a probabilidade p do evento ocorrer, temos então:
p_i = \dfrac{1}{1 + \mathrm{e}^{-Z_i}}
E a probabilidade do evento não ocorrer é:
1 - p_i = \dfrac{1}{1 + \mathrm{e}^{Z_i}}
Ao criarmos um gráfico de um conjunto de logitos aleatório, por exemplo de -5 à +5, temos uma curva conhecida como “curva S” ou “sigmóide”:
tibble(Z = seq(-5,5)) |>
mutate (p = 1/(1 + exp(1)^(Z*-1))) |>
ggplot(aes(Z,p)) +
geom_point(size = 3) +
geom_line(linetype = "dashed")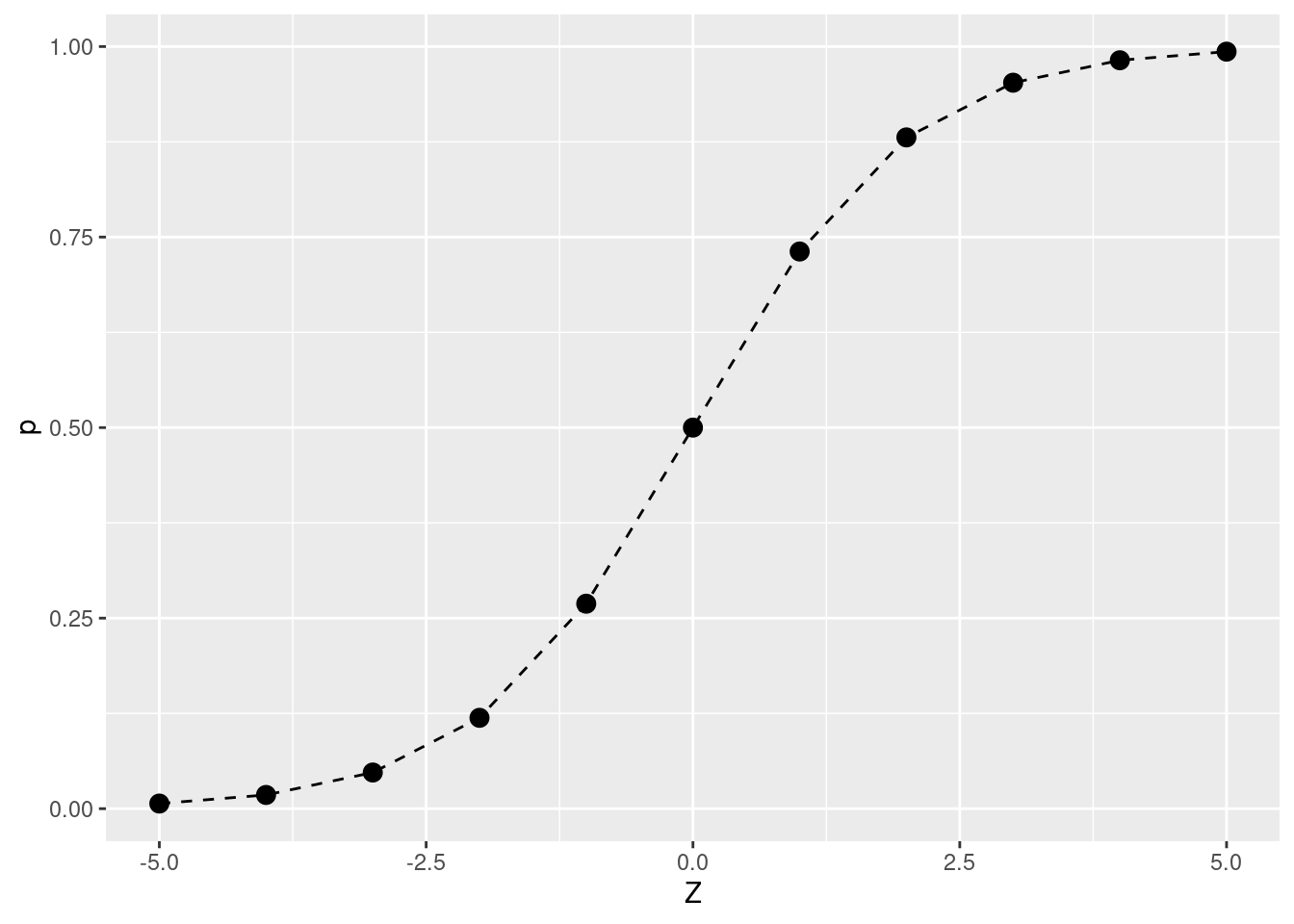
Tabela
tab <- tibble(Z = seq(-6,6)) |>
mutate (p = 1/(1 + exp(1)^(Z*-1))) |>
mutate (chance = round(exp(Z),4))
tabEntão, quando calcularmos o logito em função das variáveis explicativas, conseguiremos estimar a probabildade do evento ocorrer.
Enquanto na regressão linear, utilizamos os mínimos quadrados ordinários (OLS) para fazer as estimativas dos coeficientes, aqui iremos estimar os coeficientes maximizando a função de verossimilhança (likelihood).
LL=\sum_{n=i}^{n} [(Y_i) * ln(\dfrac {\mathrm{e}^{Z_i}} {1 + \mathrm{e}^{Z_i}})] + [(1-Y_i) * ln(\dfrac {1} {1 + \mathrm{e}^{Z_i}})] = máx
Fazemos isto, pois queremos maximizar a probabildade do evento ocorrer em cada uma das observações da amostra. Isto gera uma função produtória, que após manupulações matemáticas, torna-se a função somatória apresentada anteriormente. É por isso que pretendemos maximizar a função logaritima de verossimilhança (maximum likelihood estimation - MLE).
O cáculo dos coeficientes \alpha e \beta para maximizar a função de verossimilhança é feito automaticamente quando criamos um modelo de regressão logística binária no R, porém, iremos apenas exemplificar, como isto poderia ser feito manualmente.
Vamos criar uma função que calcula o log da verossimilhança e através da função optim() iremos buscar os valores de \alpha e \beta para que este log (log likelihood) seja o maior possível.
# Para simplificar, vamos criar uma função da sigmoid, ou seja, a partir do logito conseguimos calcular a probabilidade.
sigmoid <- function (z) {
p <- 1/(1+exp((-z)))
return (p)
}
# Agora vamos definir a função de máxima verossimilhança (neste caso é também chamada de cost-função (ll) )
LL <- function(X, y, par){
n <- length(y)
p <- sigmoid(X%*%par)
J1 <- (1/n) * sum((-y * log(p)) - ((1-y) * log((1-p))))
J2 <- sum((y * log(p)) + ((1-y) * log((1-p))))
return (J2)
}
# Definimos nossas variáveis explicativas em X (incluindo uma coluna com 1 do alpha e um vetor dependente em y. Definimos também valores inicias para o alpha e betas com zeros.
X <- cbind(rep(1,length(df$sex)),as.numeric(df$sex)-1)
y <- as.numeric(df$survived) - 1
alpha_beta_iniciais <- c(0,0)
# Usamos a função optim() com fnscale=-1 para MAXIMIZAR a função LL
estimador <- optim(par = alpha_beta_iniciais, X = X, y = y, fn = LL, control=list(fnscale=-1, trace=TRUE)) Nelder-Mead direct search function minimizer
function value for initial parameters = 907.329659
Scaled convergence tolerance is 1.35203e-05
Stepsize computed as 0.100000
BUILD 3 934.432971 907.329659
EXTENSION 5 924.415228 879.977468
EXTENSION 7 907.329659 841.022564
EXTENSION 9 879.977468 781.312129
EXTENSION 11 841.022564 732.458819
EXTENSION 13 781.312129 699.228362
LO-REDUCTION 15 732.458819 699.228362
HI-REDUCTION 17 712.469564 699.228362
REFLECTION 19 707.984003 698.495122
REFLECTION 21 699.228362 690.158637
LO-REDUCTION 23 698.495122 690.158637
REFLECTION 25 691.466804 688.135233
HI-REDUCTION 27 690.158637 688.135233
EXTENSION 29 688.261810 684.404451
LO-REDUCTION 31 688.135233 684.404451
REFLECTION 33 685.874068 684.176646
LO-REDUCTION 35 684.461674 684.176646
HI-REDUCTION 37 684.404451 684.150972
HI-REDUCTION 39 684.176646 684.099201
HI-REDUCTION 41 684.150972 684.083316
REFLECTION 43 684.099201 684.072921
HI-REDUCTION 45 684.083316 684.061823
HI-REDUCTION 47 684.072921 684.053724
HI-REDUCTION 49 684.061823 684.053724
LO-REDUCTION 51 684.057011 684.051875
HI-REDUCTION 53 684.053724 684.051875
HI-REDUCTION 55 684.052272 684.051787
HI-REDUCTION 57 684.051875 684.051623
HI-REDUCTION 59 684.051787 684.051575
HI-REDUCTION 61 684.051623 684.051554
HI-REDUCTION 63 684.051575 684.051538
HI-REDUCTION 65 684.051554 684.051535
Exiting from Nelder Mead minimizer
67 function evaluations usedpaste("Alpha:",estimador$par[1], " Beta:",estimador$par[2])[1] "Alpha: 0.981851386441049 Beta: -2.42527280045556"paste("LogLikelihood: ",estimador$value)[1] "LogLikelihood: -684.051528079323"Veja que os coeficientes de \alpha = 0.98 e \beta = -2.42 serão muito similares aos que encontraremos quando criarmos o modelo pela função glm(). O valor maximizado do log da função de verossimilhança (log likelihood), também será similar ao loglik do modelo quando criado através da função glm().
Usaremos a função glm() do R para criar o modelo.
Vamos inicalmente criar um modelo logístico binomial simples, ou seja, com apenas a variável dependente (survived) e uma variável explicativa (sex).
#Criando o modelo:
modelo_log_bin_01 <- glm(formula = survived ~ sex, family = "binomial", data = df)
modelo_log_bin_01
Call: glm(formula = survived ~ sex, family = "binomial", data = df)
Coefficients:
(Intercept) sexmale
0.9818 -2.4254
Degrees of Freedom: 1308 Total (i.e. Null); 1307 Residual
Null Deviance: 1741
Residual Deviance: 1368 AIC: 1372Para obter o valor máximo da função de verossimilhança (loglike), podemos utilizar a função logLik().
logLik(modelo_log_bin_01)'log Lik.' -684.0515 (df=2)Observe o uso do parâmetro family=“binomial” para que a função glm() entenda que queremos uma distribuição de bernoulli.
Já que não fizemos a criação da variável dependente dummy manualmente, é importante sabermos o que estamos tratando como “evento”, pois o “yes” e “no” da variável não necessariamente determina a probabildade do evento.
Podemos definir manualmente 0 para o não evento e 1 para o evento em nosso dataset, mas como temos a variável do tipo fator (factor), o R pega o primeiro nível por ordem alfabética e define como não evento e o outro como evento. Veja:
levels (df$survived)[1] "no" "yes"Veja que os mesmos coeficientes do modelo são apresentados se ajustarmos manualmente a variável.
df |>
mutate (survived = case_when(survived == "no" ~ 0,
TRUE ~ 1)) %>%
glm(formula = survived ~ sex, family = "binomial", data = .) -> modelo_log_bin_02
jtools::export_summs(modelo_log_bin_01, modelo_log_bin_02, scale = F, digits = 4)| Model 1 | Model 2 | |
|---|---|---|
| (Intercept) | 0.9818 *** | 0.9818 *** |
| (0.1040) | (0.1040) | |
| sexmale | -2.4254 *** | -2.4254 *** |
| (0.1360) | (0.1360) | |
| N | 1309 | 1309 |
| AIC | 1372.1031 | 1372.1031 |
| BIC | 1382.4571 | 1382.4571 |
| Pseudo R2 | 0.3370 | 0.3370 |
| *** p < 0.001; ** p < 0.01; * p < 0.05. | ||
A função summ() do pacote jtools também nos dá o \chi^2 do modelo. Neste caso, o \chi^2 é similar ao teste F do modelo de regressão linear, ou seja, se ao menos um beta for estatisticamente significativo, temos um modelo.
jtools::summ(modelo_log_bin_01)| Observations | 1309 |
| Dependent variable | survived |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| 𝛘²(1) | 372.92 |
| Pseudo-R² (Cragg-Uhler) | 0.34 |
| Pseudo-R² (McFadden) | 0.21 |
| AIC | 1372.10 |
| BIC | 1382.46 |
| Est. | S.E. | z val. | p | |
|---|---|---|---|---|
| (Intercept) | 0.98 | 0.10 | 9.44 | 0.00 |
| sexmale | -2.43 | 0.14 | -17.83 | 0.00 |
| Standard errors: MLE |
Observe também que a variável explicativa sexo (sex) deve ser “dummizada”. Não fizemos este processo manualmente, pois a função glm() já entende este processo devido ao tipo da variável no dataset ser do tipo fator (factor). Mas podemos confirmar que a variável referência foi a “female”, devido à ordem no fator.
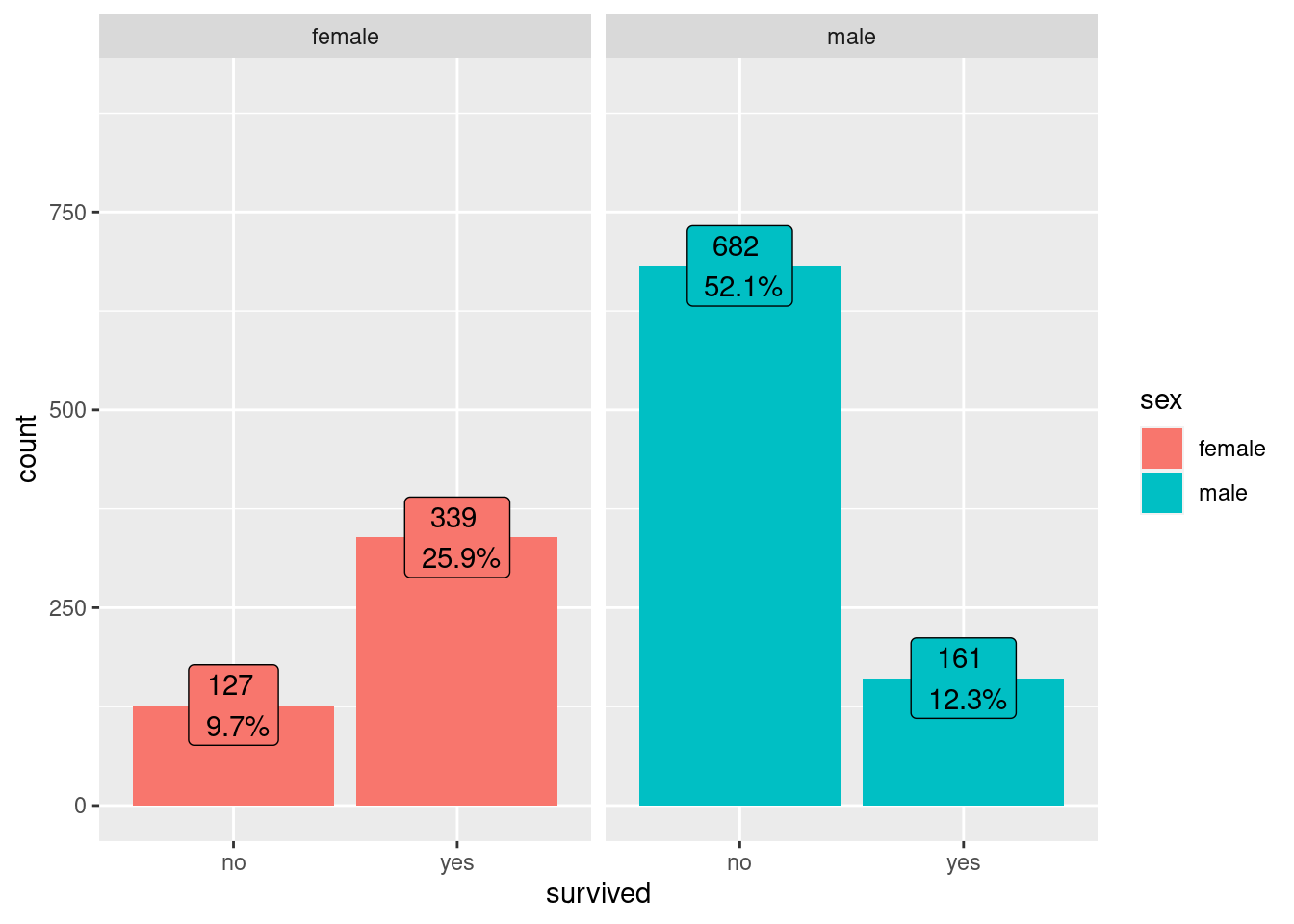
levels(df$sex)[1] "female" "male" Vamos inicialmente visualizar as porcentagens dos sobreviventes agrupados pelo sexo:
#Criando uma função auxiliar para agrupar duas variáveis categoricas
#no ggplot, mas mostrar as proporções em apenas uma
prop_per_x <- function(x, count){
df_tmp <- tibble( x = x, count = count)
tmp <- df_tmp |> group_by(x) |> summarise(n = sum(count))
prop <- left_join(df_tmp, tmp) |> mutate (prop = count/n)
return (prop$prop)
}
#Criando os gráficos
df |> dplyr::select(survived,sex) |> ggplot(aes(survived, fill = sex))+
geom_bar(position='dodge2')+
geom_label(aes(
label=paste(count,"\n",scales::label_percent(accuracy = 0.1)(after_stat(prop_per_x(x, count))))
),
stat = "count",
position = position_dodge2(width = 0.9),
show.legend = FALSE
)+
geom_label(stat="count",
aes(
label = paste(..count..,"\n",scales::label_percent(accuracy = 0.1)
(..count../sum(..count..))),
group = survived),
show.legend = F,
position = position_stack( vjust = 1.05)) +
scale_y_continuous(limits = c(NA,900))
df |> dplyr::select(survived,sex) |> ggplot(aes(survived, fill = sex))+
geom_bar(position='dodge2')+
geom_label(stat="count",
aes(
label = paste(..count..,"\n",scales::label_percent(accuracy = 0.1)
(..count../sum(..count..))),
group = sex),
show.legend = F,
position = position_dodge2(width = 0.9)) +
facet_wrap(vars(sex)) +
scale_y_continuous(limits = c(NA,900))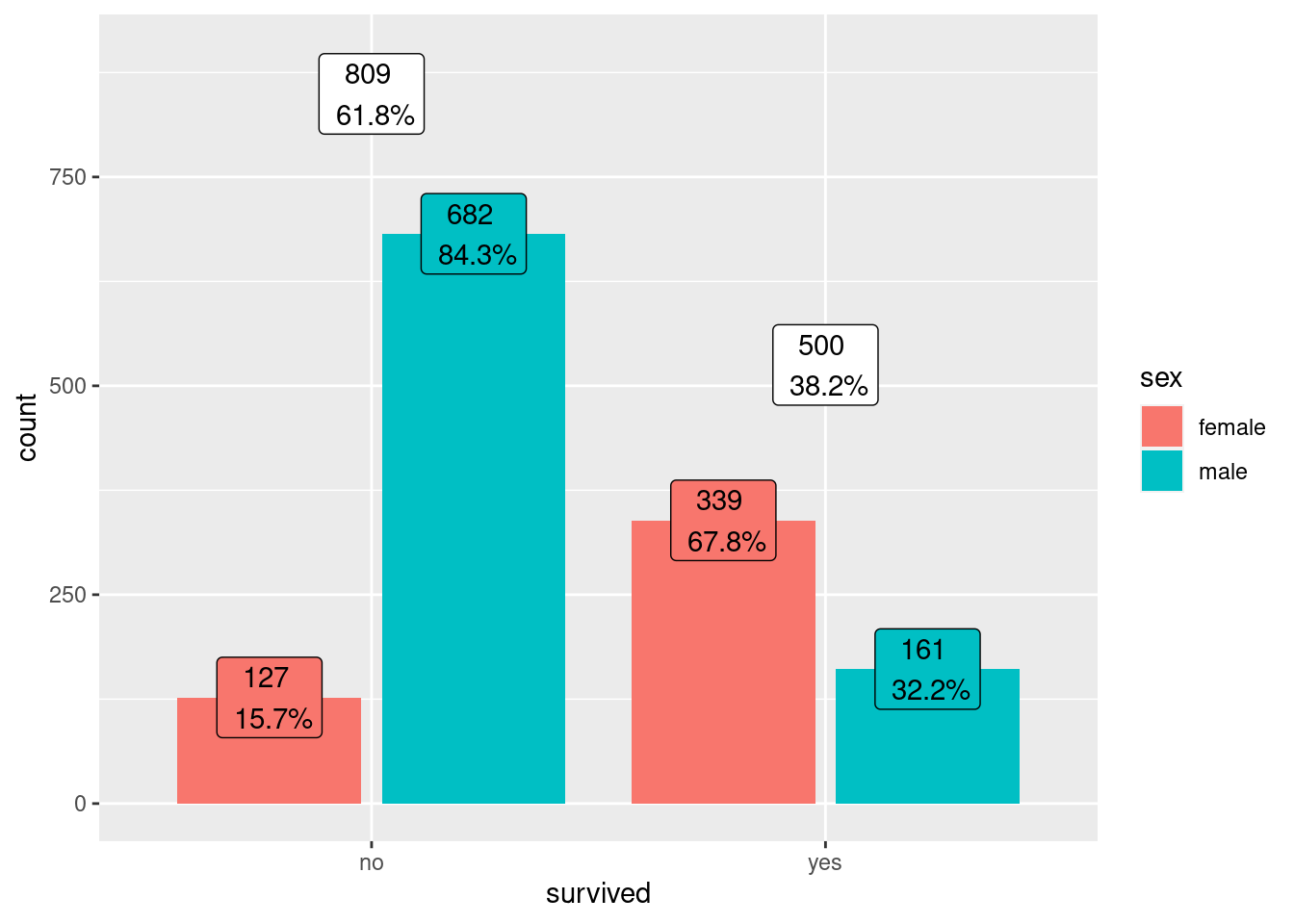
Agora vamos ver o resumo do modelo criado através da função summary()
summary(modelo_log_bin_01)
Call:
glm(formula = survived ~ sex, family = "binomial", data = df)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.6124 -0.6511 -0.6511 0.7977 1.8196
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.9818 0.1040 9.437 <2e-16 ***
sexmale -2.4254 0.1360 -17.832 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1741.0 on 1308 degrees of freedom
Residual deviance: 1368.1 on 1307 degrees of freedom
AIC: 1372.1
Number of Fisher Scoring iterations: 4Nos modelos de regressão linear, onde temos o R2 para representar a porcentagem de variância da y por se tratar de variável quantitativa, aqui, na logística binária isto não faz mais sentido, pois temos uma variável y dicotômica, então acabamos interpretando atraveś da probabilidade do evento ocorrer ou não.
Através dos valores dos coeficientes, podemos calcular nosso logito (Z), que equivale ao logaritmo natual da chance (odds), conforme vimos anteriormente:
# Obtendo os coeficientes do modelo
alpha <- coef(modelo_log_bin_01)[1]
beta <- coef(modelo_log_bin_01)[2]
X1 <- 1
# Logitos: Modelo é quando o sexo masculino é presente e nulo quando não é
Zmod <- alpha + beta * X1
Znulo <- alpha + beta * 0
#Calculo das chances (odds) e probabilidades
ChanceMod <- exp(Zmod)
ChanceNulo <- exp(Znulo)
ProbMod <- 1/(1+exp(-Zmod))
ProbNulo <- 1/(1+exp(-Znulo))
#Gráfico comparando com logitos de -6 a 6
tab |>
ggplot(aes(Z,p)) +
geom_point(size = 3) +
geom_line(linetype = "dashed")+
geom_point(aes(x=Zmod, y=ProbMod), color = "blue", size = 4) +
geom_text(aes(x=Zmod, y=ProbMod,
label=paste("Sexo=1 (Masculino)")),
position = position_nudge(x=-2),
color = "blue", size = 4) +
geom_point(aes(x=Znulo, y=ProbNulo), color = "red", size = 4)+
geom_text(aes(x=Znulo, y=ProbNulo,
label=paste("Sexo=0 (Feminino)")),
position = position_nudge(x=-2),
color = "red", size = 4) +
labs(y = "Probabilidade", x = "Logito (Z)")
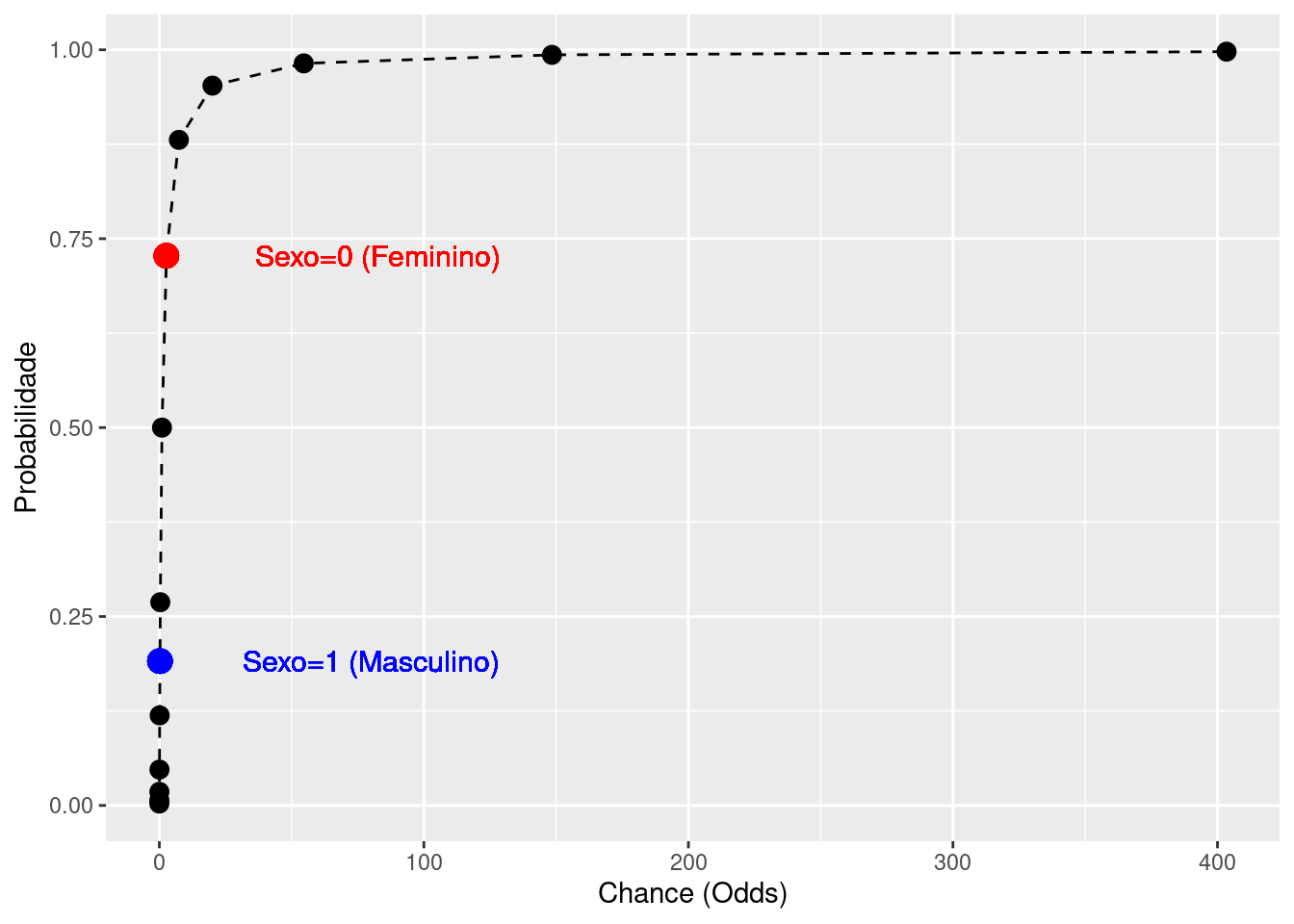
#Gráfico comparando com chances de -6 a 6
tab|>
ggplot(aes(chance,p)) +
geom_point(size = 3) +
geom_line(linetype = "dashed")+
geom_point(aes(x=ChanceMod, y=ProbMod), color = "blue", size = 4) +
geom_text(aes(x=ChanceMod, y=ProbMod,
label=paste("Sexo=1 (Masculino)")),
position = position_nudge(x=+80),
color = "blue", size = 4) +
geom_point(aes(x=ChanceNulo, y=ProbNulo), color = "red", size = 4)+
geom_text(aes(x=ChanceNulo, y=ProbNulo,
label=paste("Sexo=0 (Feminino)")),
position = position_nudge(x=+80),
color = "red", size = 4) +
labs(y = "Probabilidade", x = "Chance (Odds)")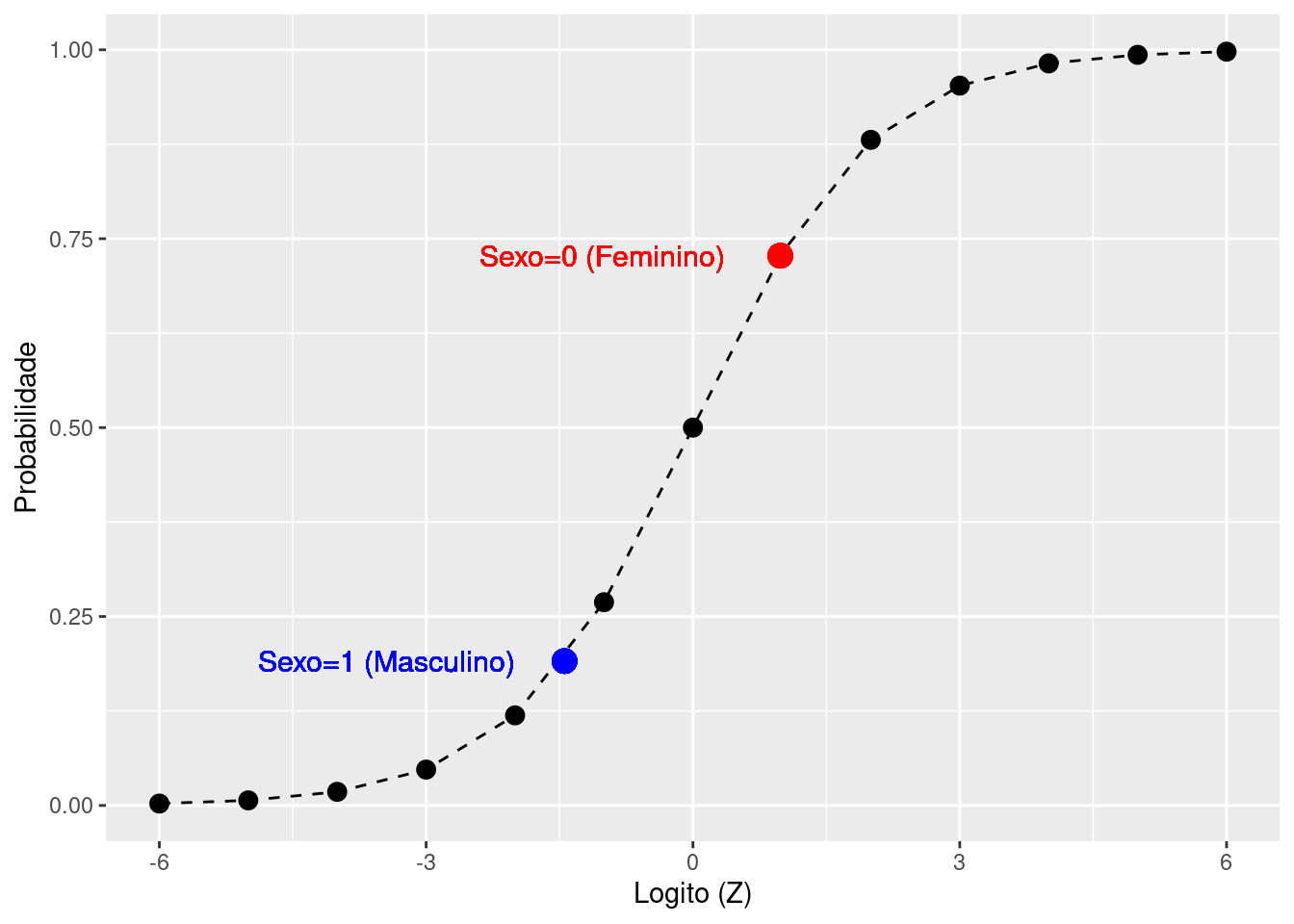
Vejamos em uma tabela estes valores:
tmp<-tibble (items = c("alpha", "beta", "X1", "Zmod", "Znulo", "ChanceMod", "ChanceNulo", "ProbMod", "ProbNulo"),
valores = round(c(alpha, beta, X1, Zmod, Znulo, ChanceMod, ChanceNulo, ProbMod, ProbNulo),3))
tmp# A tibble: 9 × 2
items valores
<chr> <dbl>
1 alpha 0.982
2 beta -2.42
3 X1 1
4 Zmod -1.44
5 Znulo 0.982
6 ChanceMod 0.236
7 ChanceNulo 2.67
8 ProbMod 0.191
9 ProbNulo 0.727Veja que a diferença da chance (odds) entre o modelo nulo e modelo é o valor do \beta de X1 (sexo) e que a chance do modelo dividida pela chance nulo é o que chamamos de razão de chance (odds ratio - OR). Isso é importante quando formos interpretar os coeficientes posteriormente.
Como temos como categoria de referência “yes”, ou seja, “sobreviveu”, na variável dependente e como categoria de referência “female” na variável X1 (sex), então os valores do modelo nulo, são referentes à probabilidade de sibrevivência das mulhares (X1=0, sex=female), enquanto que (X1=1, sex=male) são os valores de probabilidade para homens que sobreviveram. Vejam que quanto maior o valor de chance dos homens, é menor que os das mulheres, e consequentemente, sua probabildade também é menor.
Analisar o coeficiente dos betas (\beta), é utilizado para entender se a influência é maior ou menor que a do evento não ocorrer, porém, devemos lembrar que o valor do \beta corresponde ao valor da unidade logito (log da chance - log odds) da variável dependente quando dimuni-se X em uma unidade. Como pode-se notar, afimar que o ln da chance diminui em 2.425 quando a X aumenta em uma unidade não é muito interpretativo.
Por isso, em geral, analisamos a razão de chance (odds ratio - OR), ou seja, elevamos o e à potência do logito (\mathrm{e}^Z), em nosso caso, \mathrm{e}^-2.475 = 0.08843.
Neste caso, diríamos que a chance de ocorrer o evento da Y (sobreviver), diminui em 0,00884 para cada aumento na unidade de X, como X também é dicotômica, com a categoria de referência em “female”, diríamos que a chance diminui em 0,0084 vezes quando o indivídou for homem (male).
Lembre-se que, apesar de usarmos os termos “chances” e “probabilidade” de forma intercambiável em nosso cotidiano, estes conceitos NÃO são iguais: Chance é a razão entre a probabilidade de um evento ocorrer sobre a probabilidade do evento não ocorrer:
chance = \frac{p_i}{(1-p_i)}
Podemos também obter as chances (Odds Ratio - OR) através da função odds.ratio() do pacote questionr. O interessante desta opção é que já teríamos também os intervalos de confiança (que poderiam ser calculados manualmente obviamente):
questionr::odds.ratio(modelo_log_bin_01) OR 2.5 % 97.5 % p
(Intercept) 2.669291 2.183379 3.2840 < 2.2e-16 ***
sexmale 0.088439 0.067525 0.1151 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Observe que se no intervalo de confiança da chance conter o 1, ou do coeficiente conter o 0, este parâmetro não será considerado estatisticamente igual a zero para o nível de confiança aplicado.
Podemos fazer um teste de Wald para analisar a significância estatística do modelo também.
Anova(modelo_log_bin_01, type="II", test = "Wald")Analysis of Deviance Table (Type II tests)
Response: survived
Df Chisq Pr(>Chisq)
sex 1 317.96 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Uma forma comum de compararmos nossos valores previstos com nosso dados reais, é criar uma matriz de confusão, onde temos nas colunas os valores reais e nas linhas os valores previstos:
table(predict(modelo_log_bin_01, type = "response") >= 0.5, df$survived == "yes")[2:1, 2:1]
TRUE FALSE
TRUE 339 127
FALSE 161 682Em nosso exemplo, TRUE significa sobreviveu e FALSE não sobreviveu, portanto, podemos ler que acertamos 339 e erramos 161 dos sobreviventes e acertamos 682 dos não sobreviventes e erramos 127 dos não sobreviventes.
Nós também definimos um corte ou cut-off de 50%, ou seja, se a probabilidade do evento ocorrer for maior que 50% definiremos como evento, caso contrário, como não evento.
Atraveś desta matriz, utilizaremos o pacote caret com a função confusionMatrix() para calcular a Acurácia (78%), Sensitividade (67%) e Especificidade (84%) do modelo.
caret::confusionMatrix(table(predict(modelo_log_bin_01, type = "response") >= 0.5, df$survived == "yes")[2:1, 2:1])Confusion Matrix and Statistics
TRUE FALSE
TRUE 339 127
FALSE 161 682
Accuracy : 0.78
95% CI : (0.7565, 0.8022)
No Information Rate : 0.618
P-Value [Acc > NIR] : < 2e-16
Kappa : 0.5279
Mcnemar's Test P-Value : 0.05183
Sensitivity : 0.6780
Specificity : 0.8430
Pos Pred Value : 0.7275
Neg Pred Value : 0.8090
Prevalence : 0.3820
Detection Rate : 0.2590
Detection Prevalence : 0.3560
Balanced Accuracy : 0.7605
'Positive' Class : TRUE
Além da própria somatória da função de verossimilhança (log-likelihood - loglik), dois outros critérios são bastante utilizados para comparação de modelos logísticos.
AIC: Akaike’s Information Criterion e BIC: Bayesian Information Criterion.
Podemos utilizar diversas funções para obter tais valores. Aqui apresentaremos a função glance() do pacote broom:
broom::glance(modelo_log_bin_01)# A tibble: 1 × 8
null.deviance df.null logLik AIC BIC deviance df.residual nobs
<dbl> <int> <dbl> <dbl> <dbl> <dbl> <int> <int>
1 1741. 1308 -684. 1372. 1382. 1368. 1307 1309Lembre-se que quanto menor o AIC e BIC, maior acurácia tem o modelo, enquanto que o Loglik deve ser o maior possível, pois desejamos maximizar a função de verossimilhança, conforme vimos anteriormente.
Diferente de outros algoritmos com parcelas mais estocásticas para estimação de parâmetros, como Redes Neurais, Árvores de Decisões, etc, no modelo de regressão logística NÃO há a necessidade de separar amostra de treino e teste. Também não há a necessidade do balanceamento entre a proporção das categorias da variável dependente. Apenas quando soubermos a proporção da população, devemos fazer um ajuste no \alpha da equação de probabilidade, somando o log natural da razão de proporção da população e da amostra:
\alpha_{ajust} = \alpha + ln(\frac{pop_{evento}}{pop_{não\ evento}*} * \frac{amostra_{não\ evento}}{amostra_{evento}*} )
Assim com fizemos em nossos exemplos de Regressão Linear, podemos adicionar variáveis preditoras ao modelo. Para exemplificar, iremos adicionar a variável idade (age).
modelo_log_bin_mult_01 <- glm(survived ~ sex + age, data = df, family="binomial")
summary(modelo_log_bin_mult_01)
Call:
glm(formula = survived ~ sex + age, family = "binomial", data = df)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.7247 -0.6859 -0.6603 0.7555 1.8737
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 1.235414 0.192032 6.433 1.25e-10 ***
sexmale -2.460689 0.152315 -16.155 < 2e-16 ***
age -0.004254 0.005207 -0.817 0.414
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1414.6 on 1045 degrees of freedom
Residual deviance: 1101.3 on 1043 degrees of freedom
(263 observations deleted due to missingness)
AIC: 1107.3
Number of Fisher Scoring iterations: 4Com este resultado, observamos que a variável idade não passa no test z, com o p-valor maior que 5%. Então não devemos incluí-la no modelo, pois não é estatisticamente significante.
Vamos então selecionar outra variável (passengerClass) e criar outro modelo multivariado:
modelo_log_bin_mult_02 <- glm(survived ~ sex + passengerClass, data = df, family="binomial")
summary(modelo_log_bin_mult_02)
Call:
glm(formula = survived ~ sex + passengerClass, family = "binomial",
data = df)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.1089 -0.6984 -0.4741 0.7167 2.1173
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 2.1091 0.1728 12.203 < 2e-16 ***
sexmale -2.5150 0.1467 -17.145 < 2e-16 ***
passengerClass2nd -0.8808 0.1977 -4.456 8.34e-06 ***
passengerClass3rd -1.7231 0.1715 -10.047 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1741.0 on 1308 degrees of freedom
Residual deviance: 1257.2 on 1305 degrees of freedom
AIC: 1265.2
Number of Fisher Scoring iterations: 4Agora vemos que tanto a variável de classe do passageiro é estatisticamente significante para as categorias de primeira (referência, segunda e terceira classe)
Vamos agora montar nossa matriz de confusão e depois comparar os modelos:
caret::confusionMatrix(table(predict(modelo_log_bin_mult_02, type = "response") >= 0.5, df$survived == "yes")[2:1, 2:1])Confusion Matrix and Statistics
TRUE FALSE
TRUE 339 127
FALSE 161 682
Accuracy : 0.78
95% CI : (0.7565, 0.8022)
No Information Rate : 0.618
P-Value [Acc > NIR] : < 2e-16
Kappa : 0.5279
Mcnemar's Test P-Value : 0.05183
Sensitivity : 0.6780
Specificity : 0.8430
Pos Pred Value : 0.7275
Neg Pred Value : 0.8090
Prevalence : 0.3820
Detection Rate : 0.2590
Detection Prevalence : 0.3560
Balanced Accuracy : 0.7605
'Positive' Class : TRUE
E agora avaliar o AIC de cada modelo:
jtools::export_summs(modelo_log_bin_01, modelo_log_bin_mult_02, scale = F, digits = 4)| Model 1 | Model 2 | |
|---|---|---|
| (Intercept) | 0.9818 *** | 2.1091 *** |
| (0.1040) | (0.1728) | |
| sexmale | -2.4254 *** | -2.5150 *** |
| (0.1360) | (0.1467) | |
| passengerClass2nd | -0.8808 *** | |
| (0.1977) | ||
| passengerClass3rd | -1.7231 *** | |
| (0.1715) | ||
| N | 1309 | 1309 |
| AIC | 1372.1031 | 1265.2221 |
| BIC | 1382.4571 | 1285.9302 |
| Pseudo R2 | 0.3370 | 0.4201 |
| *** p < 0.001; ** p < 0.01; * p < 0.05. | ||
Podemos também fazer um lilelihood ratio test usando a função lrtest() do pacote lmtest para confirmarmos estatisticamente se um modelo é significativamente diferente do outro.
Observamos que o modelo multivariado com a variável classe do passageiro, possui um AIC menor, porém com uma acurácia similar ao anterior, portanto, considerando a regra da parssimonia, iremos considerar o modelo mais simples, como escolha. Lembrando que ideia do artigo, é apenas introduzir os conceitos de regressão logística.
Outra forma de avaliar o modelo, é através da área sob a curva ROC (AUC).
ROC <- pROC::roc(response = df$survived, predictor = modelo_log_bin_01$fitted.values)
ggplotly(
pROC::ggroc(ROC, color = "#440154FF", size = 1) +
geom_segment(aes(x = 1, xend = 0, y = 0, yend = 1),
color="grey40",
size = 0.2) +
labs(x = "Especificidade",
y = "Sensitividade",
title = paste("Área abaixo da curva:",
round(ROC$auc, 3),
"|",
"Coeficiente de Gini",
round((ROC$auc[1] - 0.5) / 0.5, 3))) +
theme_bw()
)ROC$aucArea under the curve: 0.7605Os procedimentos stepwise, criação de dummies e entendimento dos níveis de significância visto no modelo de regressão linear, ainda se aplicam no caso dos modelos logísticos.
Quando nossa variável depedente (y) qualitativa possui 3 ou mais categorias, devemos criar um modelo multinomial. Diferente da regressão binária, que segue uma função bernoulli, neste caso ela segue uma função binomial (o que gera confusão, pois a fução glm(), usa family=binomial, o que é uma infelicidade).
A função de desnidade probabilidade da função binomial segue a seguinte fórmula:
p(Y_im) = \prod_{m=0}^{M-1}(p_{i_m})^{Y_{im}}
De forma similar à regressão logística binária, aqui iremos gerar uma função de verossimilhança, porém com base em dummies da variável Y, ou seja, criando um logito (Z (m-0,1,...M-1)) para cada combinação das categorias da variável dependente (M) menos uma categoria de referência.
A função de máxima verossimilhança que devemos maximizar neste caso é:
LL = \sum_{i=0}^n \sum_{m=0}^{M-1} \bigg[ (Y_{im} . ln\bigg(\frac{e^{Z_{im}}} {\sum_{m=0}^{M-1}\ .e^{Z_{im}}}\bigg]\bigg)=máx
Para criarmos um modelo multinomial, iremos utilziar a função multinom() do pacote nnet.
Neste exemplo, iremos utilizar a mesma base de dados, mas para efeitos didáticos, iremos definir nossa variável dependente como a classe do passageiro (passengerClass) que tem 3 categorias. Por isso, iremos estimas 2 logitos. Cada logito terá um \alpha e mais um \beta para cada variável explicativa (X). Aqui, usaremos apenas a variável “survived” pois já vimos que existia associação entre ambas anteriormente.
modelo_log_multinon_01<- multinom(formula = passengerClass ~ survived,
data = df)# weights: 9 (4 variable)
initial value 1438.083486
final value 1253.026713
convergedsummary (modelo_log_multinon_01)Call:
multinom(formula = passengerClass ~ survived, data = df)
Coefficients:
(Intercept) survivedyes
2nd 0.250412 -0.7696066
3rd 1.456913 -1.5567341
Std. Errors:
(Intercept) survivedyes
2nd 0.1202464 0.1669208
3rd 0.1001201 0.1433488
Residual Deviance: 2506.053
AIC: 2514.053 Vejamos também um resumo através das funções export_summ() do pacote jtools:
jtools::export_summs(modelo_log_multinon_01)| Model 1 | |
|---|---|
| (Intercept) | 0.25 * |
| (0.12) | |
| survivedyes | -0.77 *** |
| (0.17) | |
| nobs | 1309 |
| edf | 4.00 |
| deviance | 2506.05 |
| AIC | 2514.05 |
| nobs.1 | 1309.00 |
| *** p < 0.001; ** p < 0.01; * p < 0.05. | |
Infelizmente, a função summ() do pacote jtools, não suporta modelos criados pelo nnet, portanto, teremos que calcular o \chi^2 manualmente. Também não temos o teste Z de Wald na saída da função summary() e também deveremos calculá-los manualmente.
Qui2 <- function(x) {
maximo <- logLik(x)
minimo <- logLik(update(x, ~1, trace = F))
Qui.Quadrado <- -2*(minimo - maximo)
pvalue <- pchisq(Qui.Quadrado, df = 1, lower.tail = F)
df <- data.frame()
df <- cbind.data.frame(Qui.Quadrado, pvalue)
return(df)
}
Qui2(modelo_log_multinon_01) Qui.Quadrado pvalue
1 127.7655 1.263221e-29zWald <- (summary(modelo_log_multinon_01)$coefficients /
summary(modelo_log_multinon_01)$standard.errors)
paste("Z (Wald):")[1] "Z (Wald):"zWald (Intercept) survivedyes
2nd 2.08249 -4.610608
3rd 14.55166 -10.859760paste("p-value:")[1] "p-value:"round((pnorm(abs(zWald), lower.tail = F) * 2), 4) (Intercept) survivedyes
2nd 0.0373 0
3rd 0.0000 0Através da função predict() iremos calcular as probabilidades das classes de passageiros de alguém que sobreviveu e outro que não sobreviveu:
p_sobreviente_0 <- predict(modelo_log_multinon_01,
data.frame(survived = "no"),
type = "probs")
p_sobreviente_1 <- predict(modelo_log_multinon_01,
data.frame(survived = "yes"),
type = "probs")
df_tmp2 <- tibble("0" = p_sobreviente_0, "1"=p_sobreviente_1, classe=c("1a", "2a", "3a")) |>
pivot_longer(cols = c("0","1"), names_to = "sobrevivente", values_to = "probabilidades") |>
mutate (probabilidades = round(probabilidades, 2))
df_tmp2 |> ggplot(aes(sobrevivente, probabilidades, color=classe)) +
geom_point(size = 4)+
geom_text(aes(label=classe),
show.legend = F,
position = position_nudge(x=-.08))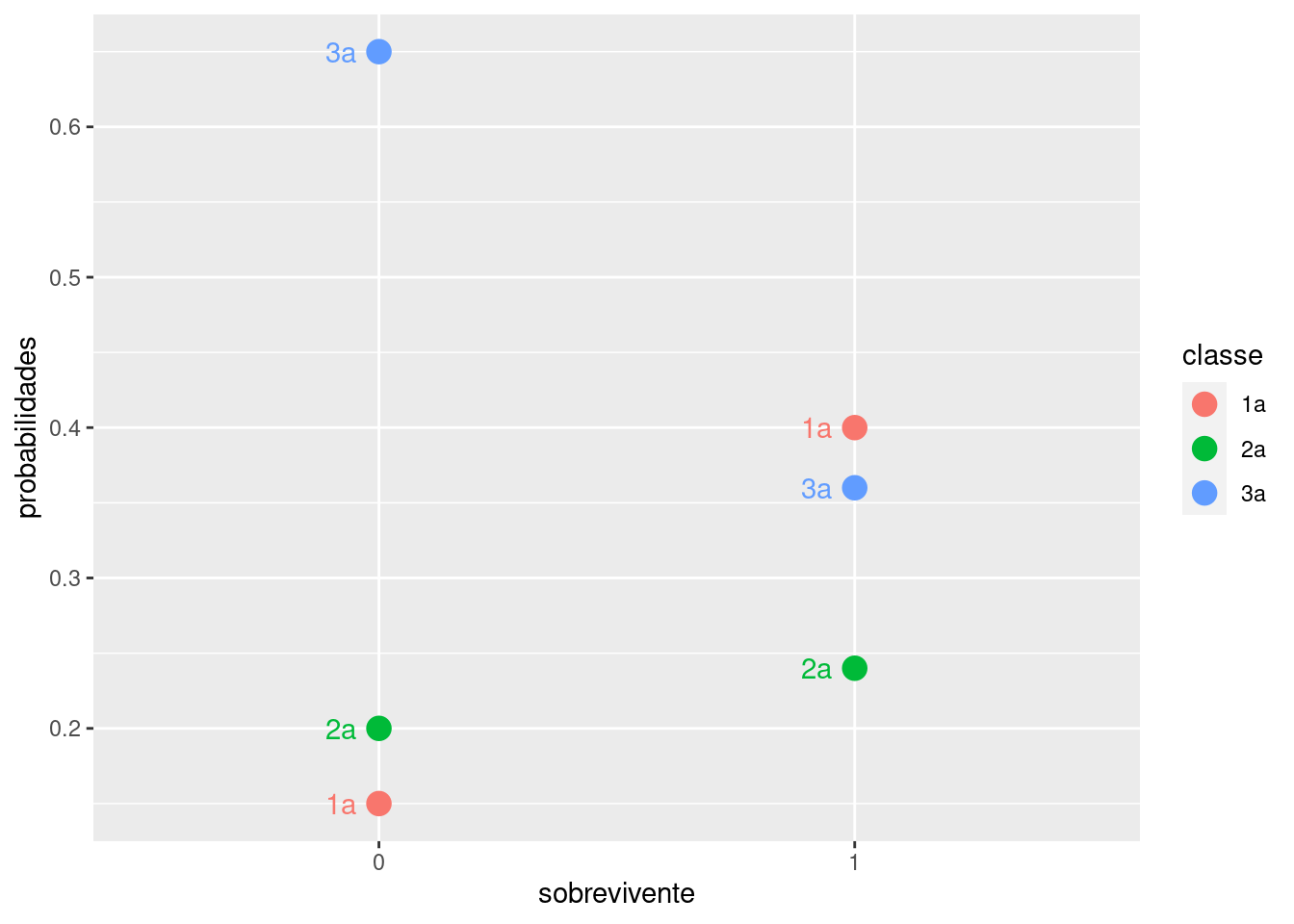
df_tmp2# A tibble: 6 × 3
classe sobrevivente probabilidades
<chr> <chr> <dbl>
1 1a 0 0.15
2 1a 1 0.4
3 2a 0 0.2
4 2a 1 0.24
5 3a 0 0.65
6 3a 1 0.36Podemos observar que a probabilidade de alguém da 1a classe não ter sobrevivido é de 15%, enquanto que desse alguém ter sobrevivido de 40%.
Podemos também pedir a classe, que é a com maior probabilidade, através da função predict()
p_sobreviente_1c <- predict(modelo_log_multinon_01,
data.frame(survived = "no"),
type = "class")
p_sobreviente_1c[1] 3rd
Levels: 1st 2nd 3rdp_sobreviente_2c <- predict(modelo_log_multinon_01,
data.frame(survived = "yes"),
type = "class")
p_sobreviente_2c[1] 1st
Levels: 1st 2nd 3rdNeste exemplo, vemos que passageiros de 1a classe tinham maior probabilidade de sobreviver e os de 3a classe maior probabilidade de não sobreviver.
Iremos agora criar um novo modelo multinomial, porém adicionando a variável idade (age).
modelo_log_multinon_02<- multinom(formula = passengerClass ~ survived + age,
data = df)# weights: 12 (6 variable)
initial value 1149.148454
iter 10 value 931.130741
final value 931.088169
convergedsummary(modelo_log_multinon_02)Call:
multinom(formula = passengerClass ~ survived + age, data = df)
Coefficients:
(Intercept) survivedyes age
2nd 2.506043 -1.149800 -0.05762495
3rd 4.526573 -2.168127 -0.09509178
Std. Errors:
(Intercept) survivedyes age
2nd 0.2984031 0.1921522 0.007007152
3rd 0.2945423 0.1918753 0.007278262
Residual Deviance: 1862.176
AIC: 1874.176 Qui2(modelo_log_multinon_02) Qui.Quadrado pvalue
1 771.6426 7.899854e-170zWald <- (summary(modelo_log_multinon_02)$coefficients /
summary(modelo_log_multinon_02)$standard.errors)
paste("Z (Wald):")[1] "Z (Wald):"zWald (Intercept) survivedyes age
2nd 8.398183 -5.98380 -8.223734
3rd 15.368159 -11.29967 -13.065178paste("p-value:")[1] "p-value:"round((pnorm(abs(zWald), lower.tail = F) * 2), 4) (Intercept) survivedyes age
2nd 0 0 0
3rd 0 0 0jtools::export_summs(modelo_log_multinon_02)| Model 1 | |
|---|---|
| (Intercept) | 2.51 *** |
| (0.30) | |
| survivedyes | -1.15 *** |
| (0.19) | |
| age | -0.06 *** |
| (0.01) | |
| nobs | 1046 |
| edf | 6.00 |
| deviance | 1862.18 |
| AIC | 1874.18 |
| nobs.1 | 1046.00 |
| *** p < 0.001; ** p < 0.01; * p < 0.05. | |
Observamos pelo \chi^2 e também pela estatística z (Wald) que ambas as variáveis são estatisticamente significante à 95% de confiança.
Comparando os Modelos:
logLik(modelo_log_multinon_01)'log Lik.' -1253.027 (df=4)logLik(modelo_log_multinon_02)'log Lik.' -931.0882 (df=6)paste("AIC:")[1] "AIC:"AIC(modelo_log_multinon_01)[1] 2514.053AIC(modelo_log_multinon_02)[1] 1874.176Agora podemos juntar os fitted values em nossa base original para criarmos algumas visualizações:
#Iremos remover as linhas com missing values nas idades e juntar as colunas:
df2 <- drop_na(df)
df_fit <- predict(modelo_log_multinon_02, newdata = df2, type = "probs")
df_final <- cbind (df2, df_fit)
df_fitc <- predict(modelo_log_multinon_02, newdata = df2, type = "class")
df_final <- cbind (df_final, df_fitc)Agora podemos também criar nossa Matriz de Confusão para calcular a Acurácia do modelo:
table(df_final$df_fitc, df_final$passengerClass)
1st 2nd 3rd
1st 177 80 67
2nd 0 0 0
3rd 107 181 434acuracia <- (round((sum(diag(table(df_final$df_fitc, df_final$passengerClass))) /
sum(table(df_final$df_fitc, df_final$passengerClass))), 2))
acuracia[1] 0.58Visualizando as probabilidades de serem da 1a, 2a ou 3a classes:
df_final <-janitor::clean_names(df_final)
df_final |>
pivot_longer(cols = c("x1st", "x2nd", "x3rd")) |>
ggplot(aes(x=age, y=value)) +
geom_point(aes(color=name)) +
labs(y="probabilidade") +
facet_wrap(vars(survived))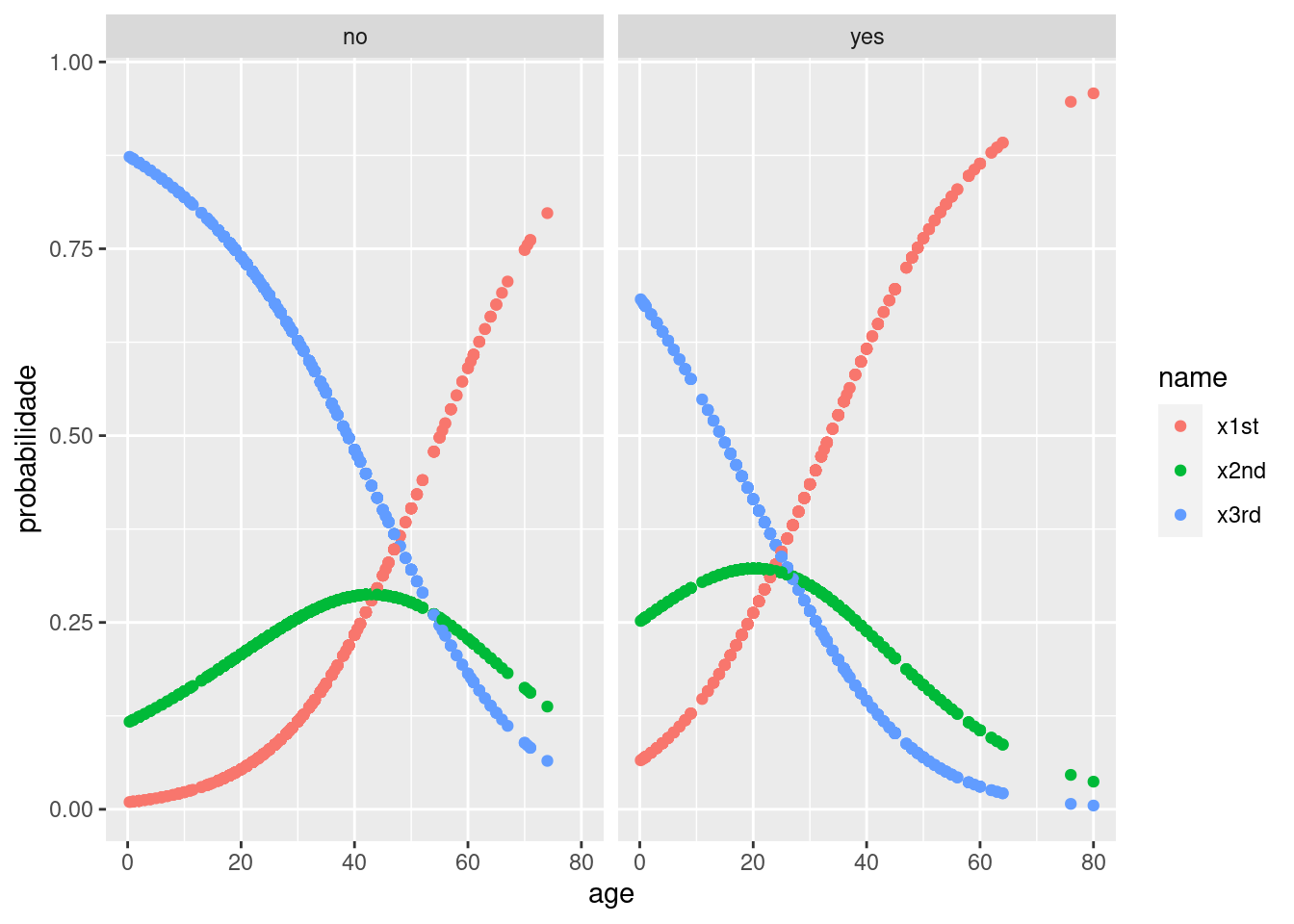
Observamos que dentre os sobreviventes, existe uma maior chance de serem adultos mais velhos da 1a classe e crianças da 3a classe. O mesmo ocorre entre aqueles que não sobreviveram, porém com maior probabilidade de serem crianças de 3a classe ser maior que os sobreviventes.
plot_ly(x = df_final$x1st,
y = df_final$age,
z = df_final$survived,
type = "mesh3d",
name = "1a classe",
intensity = df_final$x1st,
colors = colorRamp(c("red","yellow","chartreuse3","lightblue","blue"))) %>%
layout(showlegend = T,
scene = list(
xaxis = list(title = "Prob_1a_Classe"),
yaxis = list(title = "Idade"),
zaxis = list(title = "Sobreviveu")),
title = "Probabildade de ser da 1a classe")#####################################################
plot_ly(x = df_final$x2nd,
y = df_final$age,
z = df_final$survived,
type = "mesh3d",
name = "2a classe",
intensity = df_final$x2nd,
colors = colorRamp(c("chartreuse3","lightblue","blue"))) %>%
layout(showlegend = T,
scene = list(
xaxis = list(title = "Prob_2a_Classe"),
yaxis = list(title = "Idade"),
zaxis = list(title = "Sobreviveu")),
title = "Probabildade de ser da 2a classe")#####################################################
plot_ly(x = df_final$x3rd,
y = df_final$age,
z = df_final$survived,
type = "mesh3d",
name = "3a classe",
intensity = df_final$x3rd,
colors = colorRamp(c("yellow","chartreuse3","lightblue","blue"))) %>%
layout(showlegend = T,
scene = list(
xaxis = list(title = "Prob_3a_Classe"),
yaxis = list(title = "Idade"),
zaxis = list(title = "Sobreviveu")),
title = "Probabildade de ser da 3a classe")Note que aqui, as nossa variável dependente é a classe do passageiro, portanto, devemos entender que a probabilidade é do passageiro ser ou não de determinada classe e não mais se ele sobreviveu ou não.