Mostrar código-fonte
library(tidyverse)
library(janitor)
library(jtools)
library(faraway)
library (fastDummies)
library(broom)
library (MASS)
library(gghighlight)
library(overdisp)
library(pscl)library(tidyverse)
library(janitor)
library(jtools)
library(faraway)
library (fastDummies)
library(broom)
library (MASS)
library(gghighlight)
library(overdisp)
library(pscl)Diferente do que vimos no artigo sobre Regressão Linear onde criamos um modelo de ML supervisionado para fazer inferências sobre uma variável dependente contínua, neste artigo iremos criar modelos onde a variável dependente discreta obedece à uma distribuição de Poisson. Neste caso, temos uma variável dependente discreta, não-negativa e com exposição. Exposição, pode ser tempo, espaço, forma ou outro grupo latente não diretamente observável. Para simplificar, alguns exemplos de exposição podemos considerar kilometros por hora, pessoas por dia, animais por metro quadrado e assim por diante.
Em alguns cenários, temos ainda um efeito, onde a média não é igual à variância, e nestes casos, ao invés de uma distribuição Poisson, o fenômeno pode ser mais aderente à Poisson Gama, também chamada de Binomial Negativa. Observamos que quanto maior a exposição, a distribuição se aproxima de uma binomial negativa.
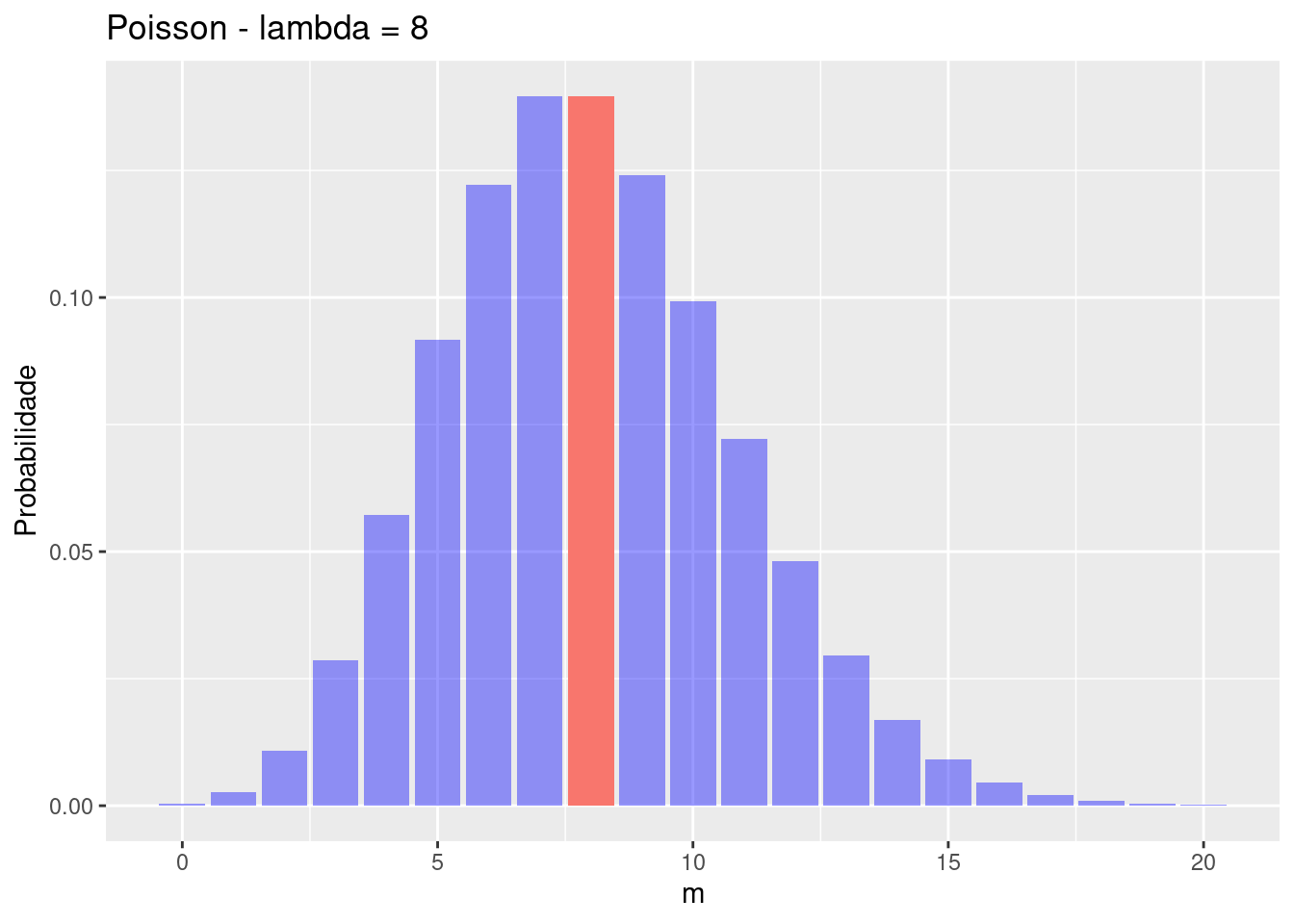
Abaixo temos uma distribuição Poisson onde o parâmetro lambda (\lambda) é igual à 4, 6 ou 8, ou seja, a média em que determinado evento ocorre por exposição são este valores.
Digamos que temos em média, 4 pessoas visitando um consultório médico a cada hora. Podemos determinar a probabilidade de termos determinado número de pessoas através da função desenidade probabilidade poisson conforme a seguir:
x <- seq(from=0, to= 20)
lmda = 4
d4 <- dpois(x, lmda)
dfp <- tibble(x,d4) |> pivot_longer(-x, names_to = "lambda", values_to = "values")
dfp |> ggplot(aes(x=x, y=values, fill=lambda)) +
geom_col(position = "dodge2", show.legend = F) +
labs (y="Probabilidade", x="m") +
gghighlight(x == lmda, unhighlighted_params = list(fill = alpha("blue", 0.4)))+
labs(title = "Poisson - lambda = 4")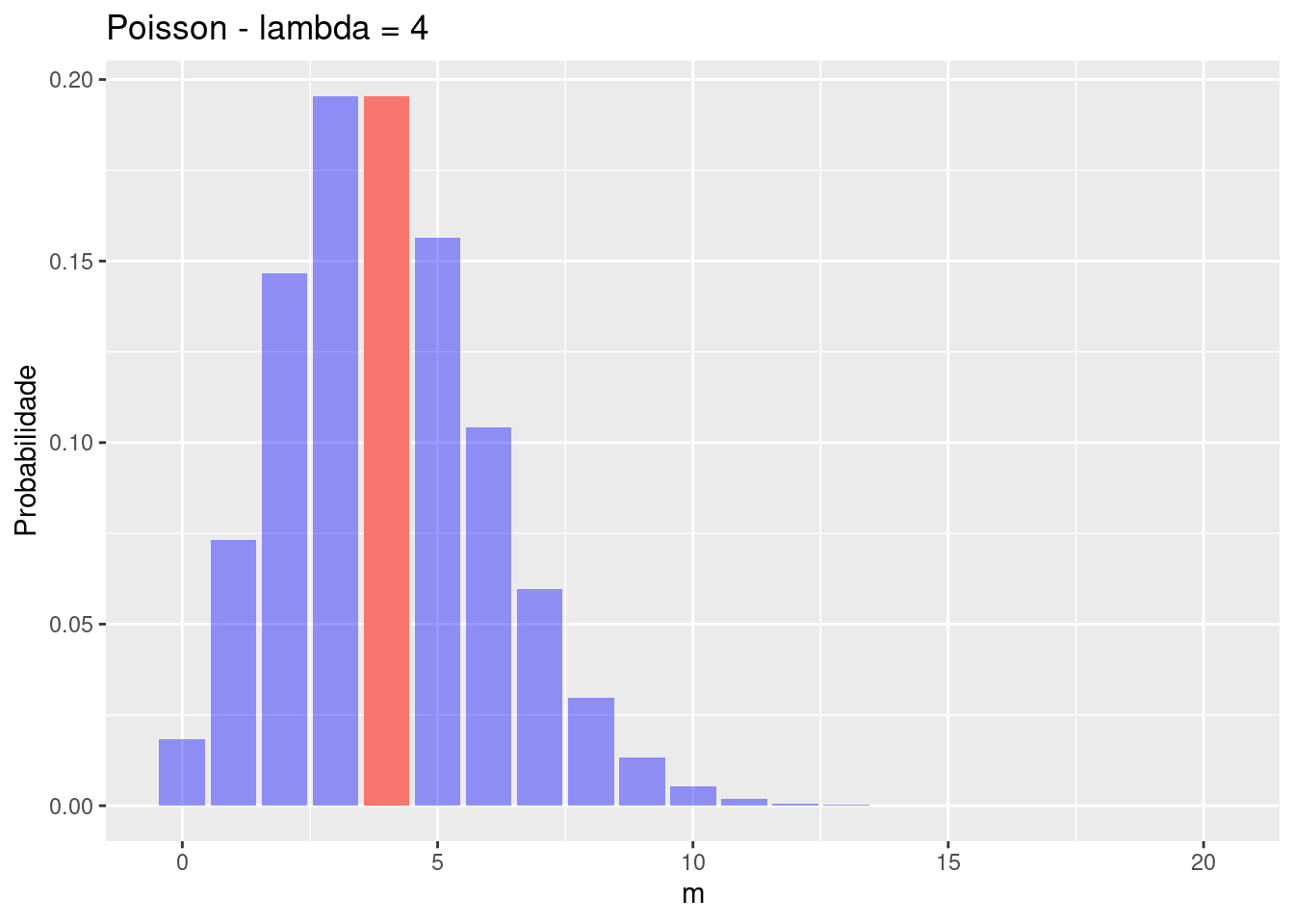
Podemos observar que a probabilidade de termos 4 pessoas no consultório é de 19% usando a função dpois():
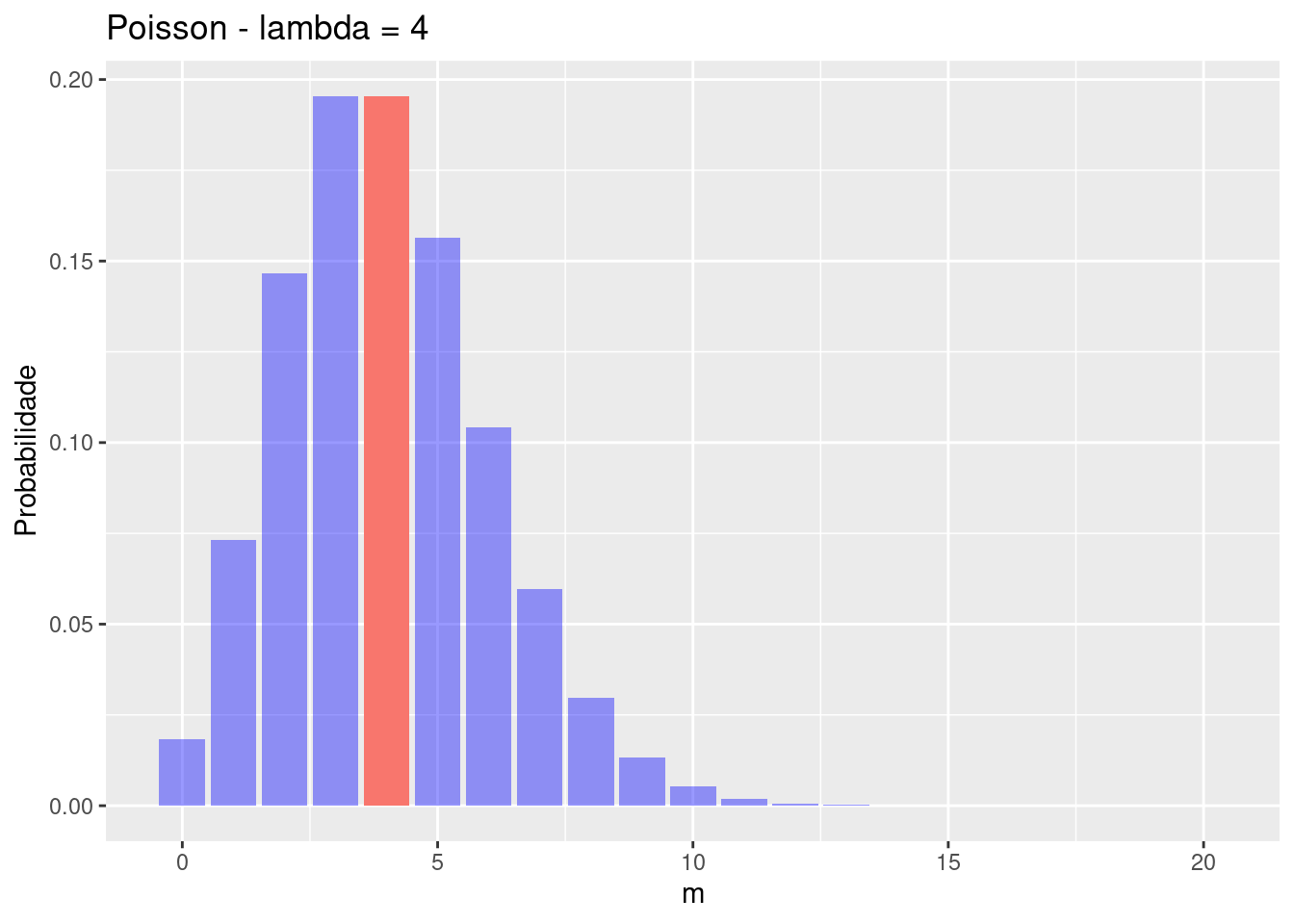
dpois(4,4)[1] 0.1953668Se aumentarmos a média pela exposição, observamos o movimentação da distribuição à direita: Veja como ficaria com lambda =1, 4 e 8:
# Lambda = 1
lmda = 1
d <- dpois(x, lmda)
dfp <- tibble(x,d) |> pivot_longer(-x, names_to = "lambda", values_to = "values")
dfp |> ggplot(aes(x=x, y=values, fill=lambda)) +
geom_col(position = "dodge2", show.legend = F) +
labs (y="Probabilidade", x="m") +
gghighlight(x == lmda, unhighlighted_params = list(fill = alpha("blue", 0.4))) +
labs(title = "Poisson - lambda = 1")
# Lambda = 4 ##########################
lmda = 4
d <- dpois(x, lmda)
dfp <- tibble(x,d) |> pivot_longer(-x, names_to = "lambda", values_to = "values")
dfp |> ggplot(aes(x=x, y=values, fill=lambda)) +
geom_col(position = "dodge2", show.legend = F) +
labs (y="Probabilidade", x="m") +
gghighlight(x == lmda, unhighlighted_params = list(fill = alpha("blue", 0.4)))+
labs(title = "Poisson - lambda = 4")
# Lambda = 8 ###########################
lmda = 8
d <- dpois(x, lmda)
dfp <- tibble(x,d) |> pivot_longer(-x, names_to = "lambda", values_to = "values")
dfp |> ggplot(aes(x=x, y=values, fill=lambda)) +
geom_col(position = "dodge2", show.legend = F) +
labs (y="Probabilidade", x="m") +
gghighlight(x == lmda, unhighlighted_params = list(fill = alpha("blue", 0.4)))+
labs(title = "Poisson - lambda = 8")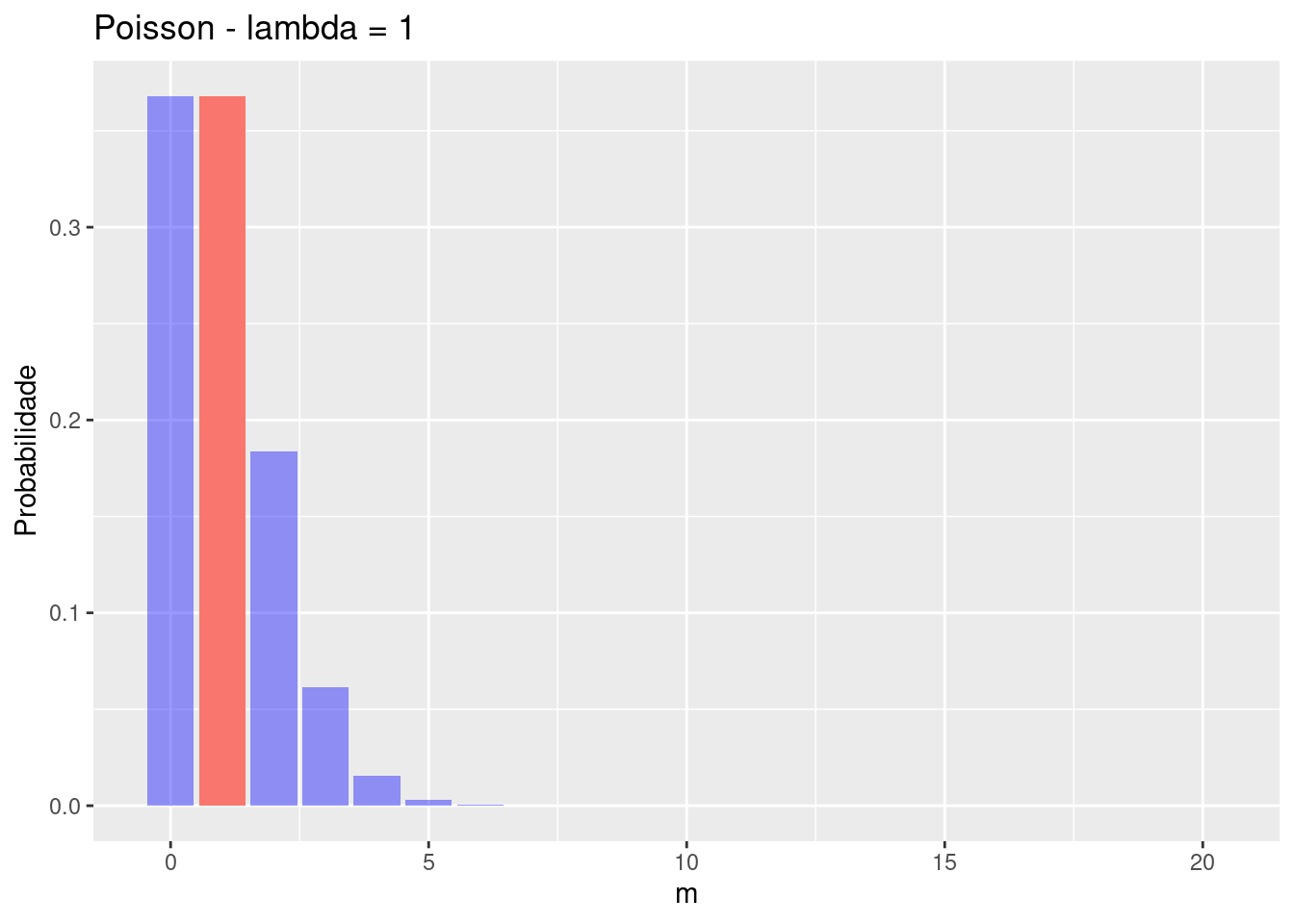
A seguir, temos um função Binomial Negativa ou Poisson Gama. Aqui, o fenômeno de superdispersão contribui para uma cauda mais alongada e é muito comum em dados de contagem. Digamos que iremos seguir nosso exemplo anterior, porém agora, a contagem de pacientes possui uma dispersão maior, ou seja, uma maior variância entre a média e os valores encontrados.
d0 <- dnbinom(x, 1, .25)
d1 <- dnbinom(x, 4, .25)
d2 <- dnbinom(x, 4, .50)
dfp <- tibble(x,d0, d1, d2) |> pivot_longer(-x, names_to = "lambda", values_to = "values")
dfp |> ggplot(aes(x=x, y=values, color=lambda)) +
geom_line()+
labs(x = "Tentativas", y="Probabilidade")+
scale_color_discrete(name = "Size-Probabilidade",
labels = c("1-25%","4-25%","4-50%"))+
theme(legend.position = "bottom")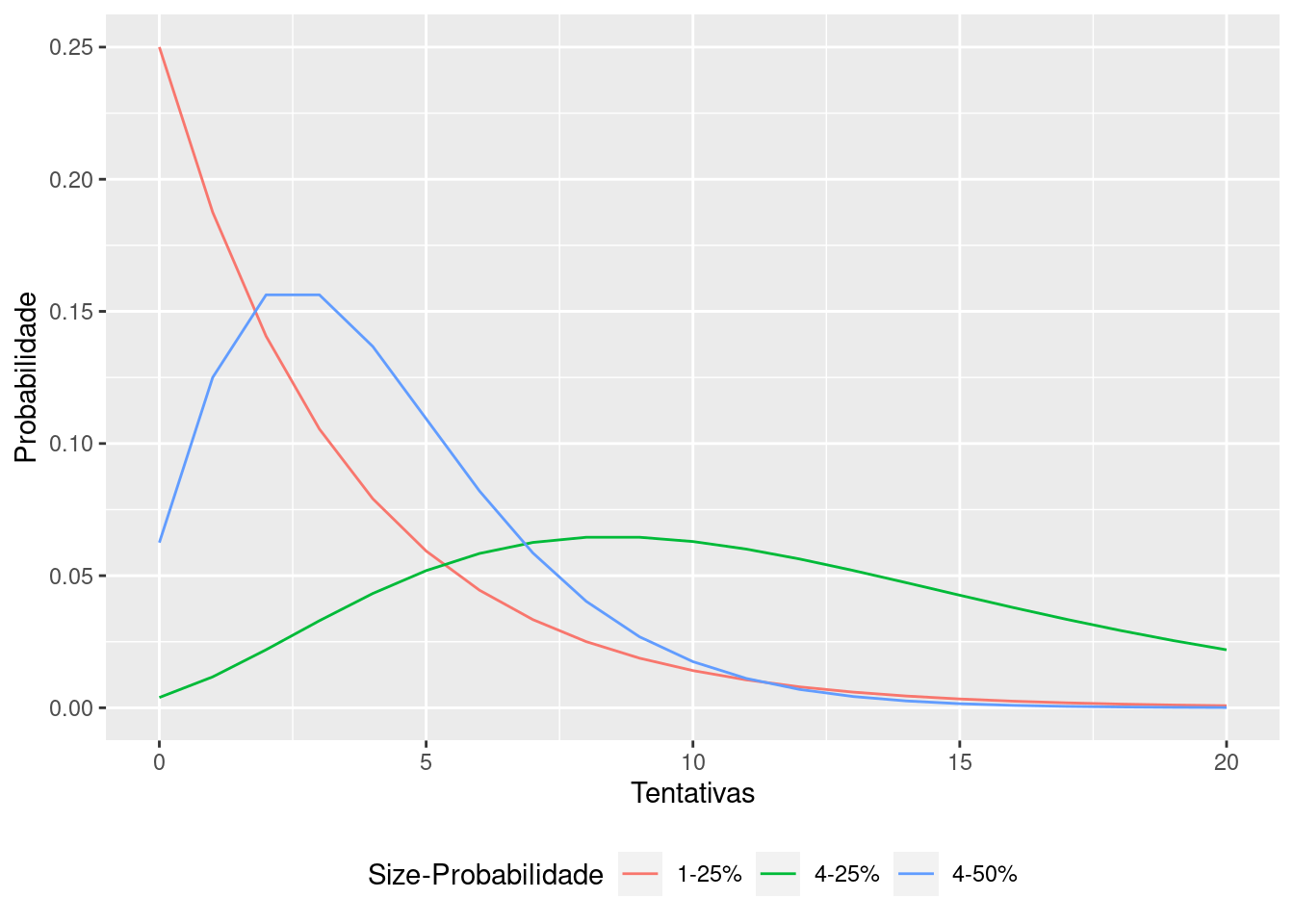
Para exemplificar os modelos para dados de contagem, iremos utilizar a base “motorins”. Esta base possui 1797 observações sobre sobre seguradoras na Suécia. Va variável dependente “Claims” contém o número de reclamos de uma seguradora em 1977.
df <- faraway::motorins
dfEm geral, devemos fazer a análise descritiva para entendermos os detalhes do dataset, porém, como o propósito deste testo é apresentar um modelo GLM para dados de contagem, iremos pular esta parte e partiremos direto para criação do modelo em função da variável zona, que são categorias geográficas do país.
modelo_poisson_01 <- glm(Claims ~ Zone, data = df, family="poisson")
modelo_poisson_01
Call: glm(formula = Claims ~ Zone, family = "poisson", data = df)
Coefficients:
(Intercept) Zone2 Zone3 Zone4 Zone5 Zone6
4.36381 -0.08423 -0.14360 0.28337 -1.13448 -0.70356
Zone7
-2.61622
Degrees of Freedom: 1796 Total (i.e. Null); 1790 Residual
Null Deviance: 391600
Residual Deviance: 364000 AIC: 371600No R, assim como fizemos na na Logiśtica Binária, utilizaremos a função glm(), porém com o parâmetro family = “poisson”. Podemos observar que a variável explicativa Zona, possui todas suas categorias com nível de significância de 5%. Vemos também que o \chi^2 também foi estatisticamente significante, portanto temos um modelo.
summary(modelo_poisson_01)
Call:
glm(formula = Claims ~ Zone, family = "poisson", data = df)
Deviance Residuals:
Min 1Q Median 3Q Max
-14.046 -10.379 -7.180 -2.447 129.117
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 4.363811 0.006569 664.303 <2e-16 ***
Zone2 -0.084230 0.009492 -8.874 <2e-16 ***
Zone3 -0.143601 0.009660 -14.866 <2e-16 ***
Zone4 0.283373 0.008631 32.834 <2e-16 ***
Zone5 -1.134481 0.014522 -78.123 <2e-16 ***
Zone6 -0.703557 0.011857 -59.335 <2e-16 ***
Zone7 -2.616223 0.040695 -64.289 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 391567 on 1796 degrees of freedom
Residual deviance: 363978 on 1790 degrees of freedom
AIC: 371630
Number of Fisher Scoring iterations: 7jtools::summ(modelo_poisson_01)| Observations | 1797 |
| Dependent variable | Claims |
| Type | Generalized linear model |
| Family | poisson |
| Link | log |
| 𝛘²(6) | 27588.58 |
| Pseudo-R² (Cragg-Uhler) | 1.00 |
| Pseudo-R² (McFadden) | 0.07 |
| AIC | 371630.09 |
| BIC | 371668.55 |
| Est. | S.E. | z val. | p | |
|---|---|---|---|---|
| (Intercept) | 4.36 | 0.01 | 664.30 | 0.00 |
| Zone2 | -0.08 | 0.01 | -8.87 | 0.00 |
| Zone3 | -0.14 | 0.01 | -14.87 | 0.00 |
| Zone4 | 0.28 | 0.01 | 32.83 | 0.00 |
| Zone5 | -1.13 | 0.01 | -78.12 | 0.00 |
| Zone6 | -0.70 | 0.01 | -59.33 | 0.00 |
| Zone7 | -2.62 | 0.04 | -64.29 | 0.00 |
| Standard errors: MLE |
Agora iremos incluir a variável explicativa “Make” que é um outro fator que representa 8 modelos de classes comuns de veículos, e os demais modelos são agrupados em uma nona categoria.
modelo_poisson_02 <- glm(Claims ~ Zone + Make, data = df, family="poisson")
modelo_poisson_02
Call: glm(formula = Claims ~ Zone + Make, family = "poisson", data = df)
Coefficients:
(Intercept) Zone2 Zone3 Zone4 Zone5 Zone6
4.22257 -0.08339 -0.14908 0.31433 -1.31050 -0.79356
Zone7 Make2 Make3 Make4 Make5 Make6
-3.42190 -1.40080 -1.73148 -1.43134 -1.29297 -0.88821
Make7 Make8 Make9
-1.61570 -2.20688 1.96871
Degrees of Freedom: 1796 Total (i.e. Null); 1782 Residual
Null Deviance: 391600
Residual Deviance: 117200 AIC: 124800summary(modelo_poisson_02)
Call:
glm(formula = Claims ~ Zone + Make, family = "poisson", data = df)
Deviance Residuals:
Min 1Q Median 3Q Max
-28.226 -3.743 -1.704 0.581 73.441
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 4.222566 0.010969 384.971 <2e-16 ***
Zone2 -0.083393 0.009492 -8.786 <2e-16 ***
Zone3 -0.149082 0.009660 -15.433 <2e-16 ***
Zone4 0.314327 0.008631 36.419 <2e-16 ***
Zone5 -1.310499 0.014524 -90.227 <2e-16 ***
Zone6 -0.793563 0.011860 -66.913 <2e-16 ***
Zone7 -3.421897 0.040706 -84.064 <2e-16 ***
Make2 -1.400800 0.021215 -66.028 <2e-16 ***
Make3 -1.731482 0.025052 -69.117 <2e-16 ***
Make4 -1.431340 0.023883 -59.931 <2e-16 ***
Make5 -1.292971 0.020230 -63.913 <2e-16 ***
Make6 -0.888214 0.017334 -51.242 <2e-16 ***
Make7 -1.615698 0.023340 -69.225 <2e-16 ***
Make8 -2.206878 0.031507 -70.044 <2e-16 ***
Make9 1.968714 0.009899 198.889 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 391567 on 1796 degrees of freedom
Residual deviance: 117153 on 1782 degrees of freedom
AIC: 124821
Number of Fisher Scoring iterations: 5jtools::summ(modelo_poisson_02)| Observations | 1797 |
| Dependent variable | Claims |
| Type | Generalized linear model |
| Family | poisson |
| Link | log |
| 𝛘²(14) | 274413.43 |
| Pseudo-R² (Cragg-Uhler) | 1.00 |
| Pseudo-R² (McFadden) | 0.69 |
| AIC | 124821.24 |
| BIC | 124903.65 |
| Est. | S.E. | z val. | p | |
|---|---|---|---|---|
| (Intercept) | 4.22 | 0.01 | 384.97 | 0.00 |
| Zone2 | -0.08 | 0.01 | -8.79 | 0.00 |
| Zone3 | -0.15 | 0.01 | -15.43 | 0.00 |
| Zone4 | 0.31 | 0.01 | 36.42 | 0.00 |
| Zone5 | -1.31 | 0.01 | -90.23 | 0.00 |
| Zone6 | -0.79 | 0.01 | -66.91 | 0.00 |
| Zone7 | -3.42 | 0.04 | -84.06 | 0.00 |
| Make2 | -1.40 | 0.02 | -66.03 | 0.00 |
| Make3 | -1.73 | 0.03 | -69.12 | 0.00 |
| Make4 | -1.43 | 0.02 | -59.93 | 0.00 |
| Make5 | -1.29 | 0.02 | -63.91 | 0.00 |
| Make6 | -0.89 | 0.02 | -51.24 | 0.00 |
| Make7 | -1.62 | 0.02 | -69.22 | 0.00 |
| Make8 | -2.21 | 0.03 | -70.04 | 0.00 |
| Make9 | 1.97 | 0.01 | 198.89 | 0.00 |
| Standard errors: MLE |
jtools::export_summs(modelo_poisson_01, modelo_poisson_02)| Model 1 | Model 2 | |
|---|---|---|
| (Intercept) | 4.36 *** | 4.22 *** |
| (0.01) | (0.01) | |
| Zone2 | -0.08 *** | -0.08 *** |
| (0.01) | (0.01) | |
| Zone3 | -0.14 *** | -0.15 *** |
| (0.01) | (0.01) | |
| Zone4 | 0.28 *** | 0.31 *** |
| (0.01) | (0.01) | |
| Zone5 | -1.13 *** | -1.31 *** |
| (0.01) | (0.01) | |
| Zone6 | -0.70 *** | -0.79 *** |
| (0.01) | (0.01) | |
| Zone7 | -2.62 *** | -3.42 *** |
| (0.04) | (0.04) | |
| Make2 | -1.40 *** | |
| (0.02) | ||
| Make3 | -1.73 *** | |
| (0.03) | ||
| Make4 | -1.43 *** | |
| (0.02) | ||
| Make5 | -1.29 *** | |
| (0.02) | ||
| Make6 | -0.89 *** | |
| (0.02) | ||
| Make7 | -1.62 *** | |
| (0.02) | ||
| Make8 | -2.21 *** | |
| (0.03) | ||
| Make9 | 1.97 *** | |
| (0.01) | ||
| N | 1797 | 1797 |
| AIC | 371630.09 | 124821.24 |
| BIC | 371668.55 | 124903.65 |
| Pseudo R2 | 1.00 | 1.00 |
| *** p < 0.001; ** p < 0.01; * p < 0.05. | ||
Conforme vimos anteriormente, quando temos superdispersão nos dados, uma função de distribuição binomial negativa pode-se adequar melhor ao modelo. Faremos um teste, usando a função overdisp() do pacote overdisp para confirmar.
overdisp::overdisp(x = df,
dependent.position = 6,
predictor.position = c(2,4))
Overdispersion Test - Cameron & Trivedi (1990)
data: df
Lambda t test score: = 18.276, p-value < 2.2e-16
alternative hypothesis: overdispersion if lambda p-value is less than or equal to the stipulated significance levelPodemos confirmar pelo p-value menor que 0.05 que temos superdispersão.
Para este modelo, iremos utilizar a função glm.nb() do pacote MASS.
df_dummy <- fastDummies::dummy_cols(.data = df,
select_columns = c("Zone", "Make"),
remove_first_dummy = T,
remove_selected_columns = T)
modelo_bneg_01 <- MASS::glm.nb(formula = Claims ~ . -Kilometres -Bonus -Insured -Payment -perd ,
data = df_dummy)
modelo_bneg_01
Call: MASS::glm.nb(formula = Claims ~ . - Kilometres - Bonus - Insured -
Payment - perd, data = df_dummy, init.theta = 1.000388793,
link = log)
Coefficients:
(Intercept) Zone_2 Zone_3 Zone_4 Zone_5 Zone_6
4.08630 -0.03357 -0.05778 0.40254 -1.04646 -0.52475
Zone_7 Make_2 Make_3 Make_4 Make_5 Make_6
-2.83441 -1.34891 -1.66316 -1.33922 -1.22828 -0.84085
Make_7 Make_8 Make_9
-1.54393 -2.10804 1.91584
Degrees of Freedom: 1796 Total (i.e. Null); 1782 Residual
Null Deviance: 6016
Residual Deviance: 1953 AIC: 14480summary(modelo_bneg_01)
Call:
MASS::glm.nb(formula = Claims ~ . - Kilometres - Bonus - Insured -
Payment - perd, data = df_dummy, init.theta = 1.000388793,
link = log)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.0955 -1.0920 -0.5114 0.1050 3.0635
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 4.08630 0.08756 46.671 < 2e-16 ***
Zone_2 -0.03357 0.08472 -0.396 0.692
Zone_3 -0.05778 0.08489 -0.681 0.496
Zone_4 0.40254 0.08357 4.817 1.46e-06 ***
Zone_5 -1.04646 0.09202 -11.372 < 2e-16 ***
Zone_6 -0.52475 0.08801 -5.962 2.48e-09 ***
Zone_7 -2.83441 0.13243 -21.403 < 2e-16 ***
Make_2 -1.34891 0.10019 -13.463 < 2e-16 ***
Make_3 -1.66316 0.10472 -15.882 < 2e-16 ***
Make_4 -1.33922 0.10887 -12.301 < 2e-16 ***
Make_5 -1.22828 0.09968 -12.322 < 2e-16 ***
Make_6 -0.84085 0.09836 -8.549 < 2e-16 ***
Make_7 -1.54393 0.10163 -15.191 < 2e-16 ***
Make_8 -2.10804 0.10712 -19.680 < 2e-16 ***
Make_9 1.91584 0.09369 20.448 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for Negative Binomial(1.0004) family taken to be 1)
Null deviance: 6015.5 on 1796 degrees of freedom
Residual deviance: 1953.4 on 1782 degrees of freedom
AIC: 14483
Number of Fisher Scoring iterations: 1
Theta: 1.0004
Std. Err.: 0.0324
2 x log-likelihood: -14450.9450 Veja que as variáveis Zone_2 e Zone_3 não se mostraram estatisticamente significantes à 5%, portante devemos fazer o procedimento stepwise. Para isto, fizemos a dummização das variáveis manualmente.
modelo_bneg_step_01 <- step(modelo_bneg_01, trace = F)
summary(modelo_bneg_step_01)
Call:
MASS::glm.nb(formula = Claims ~ Zone_4 + Zone_5 + Zone_6 + Zone_7 +
Make_2 + Make_3 + Make_4 + Make_5 + Make_6 + Make_7 + Make_8 +
Make_9, data = df_dummy, init.theta = 1.000147948, link = log)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.0970 -1.0867 -0.5155 0.1072 3.1256
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 4.05641 0.07264 55.841 < 2e-16 ***
Zone_4 0.43282 0.06782 6.382 1.75e-10 ***
Zone_5 -1.01620 0.07800 -13.029 < 2e-16 ***
Zone_6 -0.49434 0.07320 -6.753 1.44e-11 ***
Zone_7 -2.80433 0.12310 -22.781 < 2e-16 ***
Make_2 -1.34797 0.10020 -13.453 < 2e-16 ***
Make_3 -1.66153 0.10472 -15.866 < 2e-16 ***
Make_4 -1.33846 0.10887 -12.294 < 2e-16 ***
Make_5 -1.22945 0.09969 -12.332 < 2e-16 ***
Make_6 -0.84268 0.09837 -8.566 < 2e-16 ***
Make_7 -1.54565 0.10164 -15.206 < 2e-16 ***
Make_8 -2.10958 0.10713 -19.691 < 2e-16 ***
Make_9 1.91612 0.09370 20.449 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for Negative Binomial(1.0001) family taken to be 1)
Null deviance: 6014.2 on 1796 degrees of freedom
Residual deviance: 1953.5 on 1784 degrees of freedom
AIC: 14479
Number of Fisher Scoring iterations: 1
Theta: 1.0001
Std. Err.: 0.0324
2 x log-likelihood: -14451.4120 modelos <- map(list(modelo_poisson_01, modelo_poisson_02, modelo_bneg_step_01), broom::glance)
modelos <- set_names(modelos, c("modelo_poisson_01", "modelo_poisson_02", "modelo_bneg_step_01"))
modelos <- enframe(modelos)
modelos[[2]][[3]]$logLik <- as.double(modelos[[2]][[3]]$logLik)
modelos <- unnest(modelos, cols = value) |>
pivot_longer(cols = -name, names_to = "ind", values_to = "values")
modelos |> filter (ind == "AIC") |> arrange (desc(values)) |>
ggplot(aes(x=fct_reorder(name, values, .desc = values), y=values, fill = name)) +
geom_bar(stat = "identity", show.legend = F)+
geom_label(aes(label=round(values,2)), show.legend = F)+
labs(x="Modelo", y="AIC")+
theme_classic() +
theme(axis.text.x = element_text(angle = 90))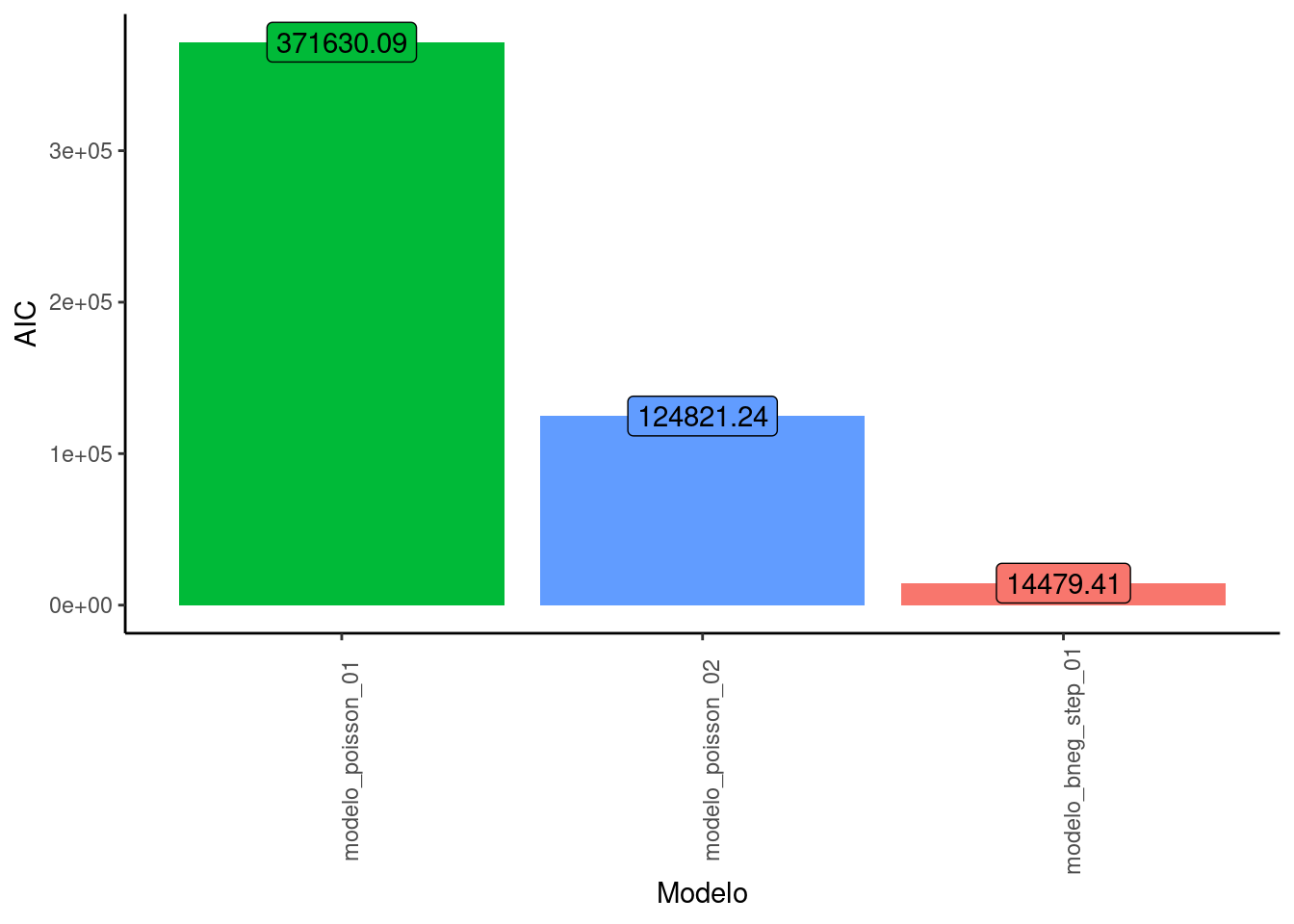
Demais indicadores:
modelos |> filter (ind %in% c("AIC", "BIC", "logLik")) |> as_tibble()# A tibble: 9 × 3
name ind values
<chr> <chr> <dbl>
1 modelo_poisson_01 logLik -185808.
2 modelo_poisson_01 AIC 371630.
3 modelo_poisson_01 BIC 371669.
4 modelo_poisson_02 logLik -62396.
5 modelo_poisson_02 AIC 124821.
6 modelo_poisson_02 BIC 124904.
7 modelo_bneg_step_01 logLik -7226.
8 modelo_bneg_step_01 AIC 14479.
9 modelo_bneg_step_01 BIC 14556.Vamos prever em nosso modelo quanto teríamos de reclamos para dois casos.
Caso 1: Alguém da Zona 4 e Fabricante 4 Caso 2: Alguém da Zona 1 e Fabricante 1
df_new <- data.frame("Zone" = factor(4,levels=c(1,2,3,4,5,6,7)),
"Make" = factor(3,levels=c(1,2,3,4,5,6,7,8,9))
)
df_new <- rbind(df_new, c(1,1))
df_new_d <- fastDummies::dummy_cols(.data = df_new,
select_columns = c("Zone", "Make"),
remove_first_dummy = T,
remove_selected_columns = T)
df_new$fit <- exp(predict(modelo_bneg_step_01, type = "link", newdata=df_new_d))
df_new$fit_p <- predict(modelo_poisson_02, type = "response", newdata=df_new)
df_new$fit <- round(df_new$fit,0)
df_new$fit_p <- round(df_new$fit_p,0)Vejamos quais seriam mas médias para tais comnimações em nossos dados:
df |> group_by(Zone, Make) |>
summarise(media = mean(Claims)) |>
filter(Zone %in% c("4","1"), Make %in% c("3", "1"))Vemos que para a Zona 4 e Make 3, a média seria de 15, enquanto que para Zona 1 e Make 1 de 62.
Nossa predição seria de 17 e 58 respectivamente para o modelo binomial e 17 e 68 para o poisson multivariado:
df$fit_p <- predict(modelo_poisson_02, type = "response")
df$fit <- exp(predict(modelo_bneg_step_01, type = "link"))
df <- df |> mutate (fit = round(fit,0),
fit_p = round(fit_p,0))
df |>
ggplot(aes(x = Make))+
geom_point(aes(y = log(Claims), color = Make), size = 1, alpha = 0.7, show.legend = T) +
geom_point(aes(y = log(fit_p)), shape = 10, color = "red", size = 3, alpha = 0.5, show.legend = F ) +
geom_point(aes(y = log(fit)),shape = 23, color = "blue", size = 3, alpha = 0.5, show.legend = F) +
facet_wrap(vars(Zone), scales = "free")+
labs(title = "Previsões usando Zona e Fabricantes\n pela Poisson e Binomial Negativa")+
theme_minimal()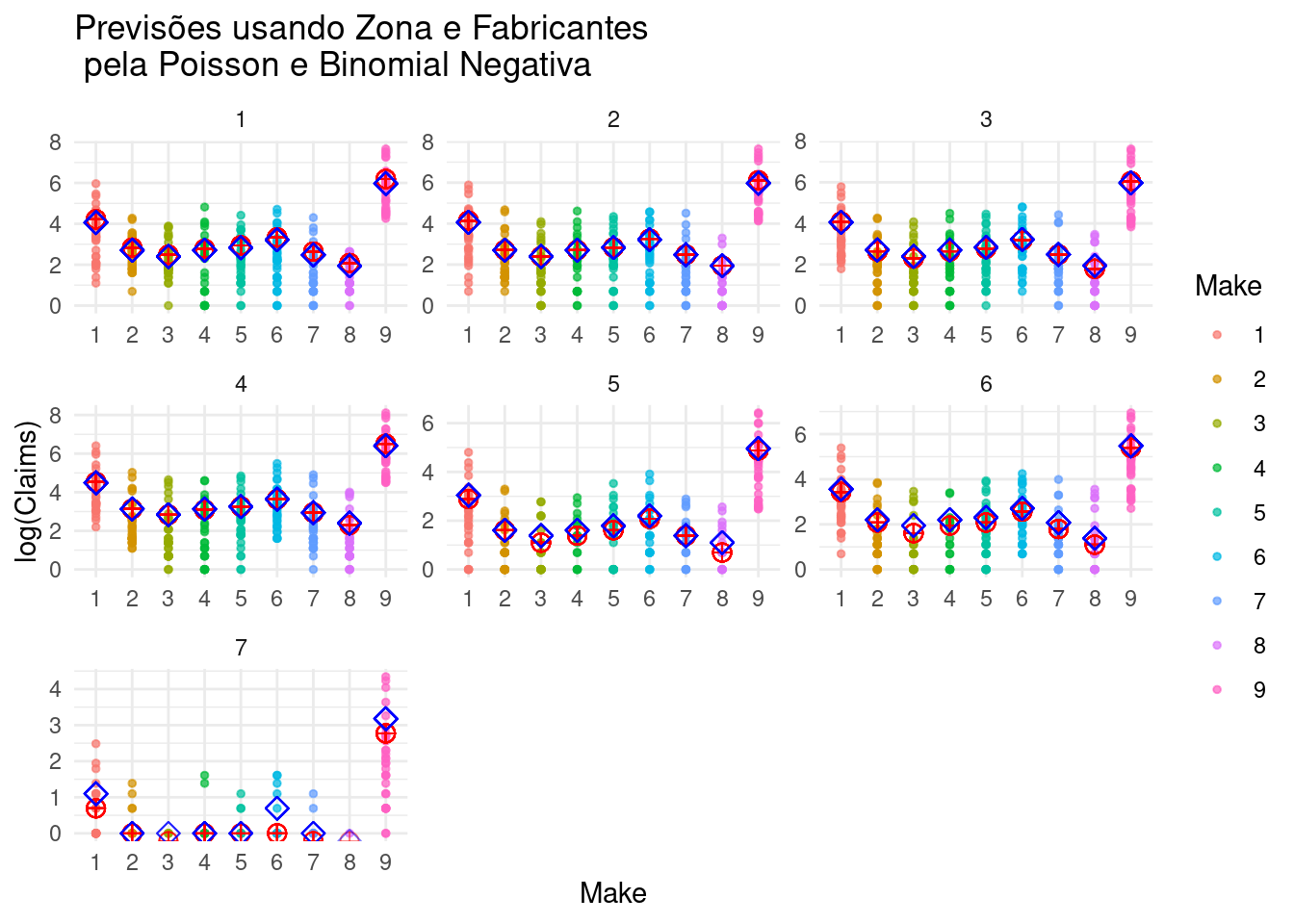
Acima, vemos os valores previstos pelo modelo usando a Binamial Negativa (em azul) e a Poisson (em vermelho) para cada Fabricante (Maker) e em cada Zona.
Em resumo, conforme comprovamos, quando temos uma superdispersão nos dados, usar um modelo com a distribuições Binomial Negativa gera um melhor ajuste (aqui usando o AIC como indicador) que uma Poisson para dados de contagem.
Em alguns casos, em nossos dados podemos ter uma grande quantidade de zeros, como por exemplo, em estudos de doenças raras, onde apenas alguns dentre muitos casos são eventos do estudo. Ou então estudos sobre fraudes e assim por diante. Nestes casos, podemos criar modelos Poisson o Binomial Negativa com inflações de zero (zero inflated). Estes modelos são conhecidos como modelos ZIP.
Apenas para exemplificar, podemos criar um modelo através da função zeroinfl() do pacote pscl. Mas antes, iremos artificialmente alterar nossa variável dependente e incluir vários casos, onde temos zeros na contagem.
# Ajustando o dataset para exemplificar o usa de modelos ZIP
df_zip <-
df_dummy |>
mutate (Claims = case_when (Claims <= 30 ~ 0L,
TRUE ~ Claims)) |>
dplyr::select(Claims, starts_with(c("Zone", "Make")))Veja que neste caso, nossa variável dependente agora possui um alto número de observações com zero reclamas (Claims) e ainda assim, precisamos estivar o modelo.
df_zip |>
ggplot(aes(x=Claims))+
geom_histogram(fill="darkred", color="white")+
theme_minimal()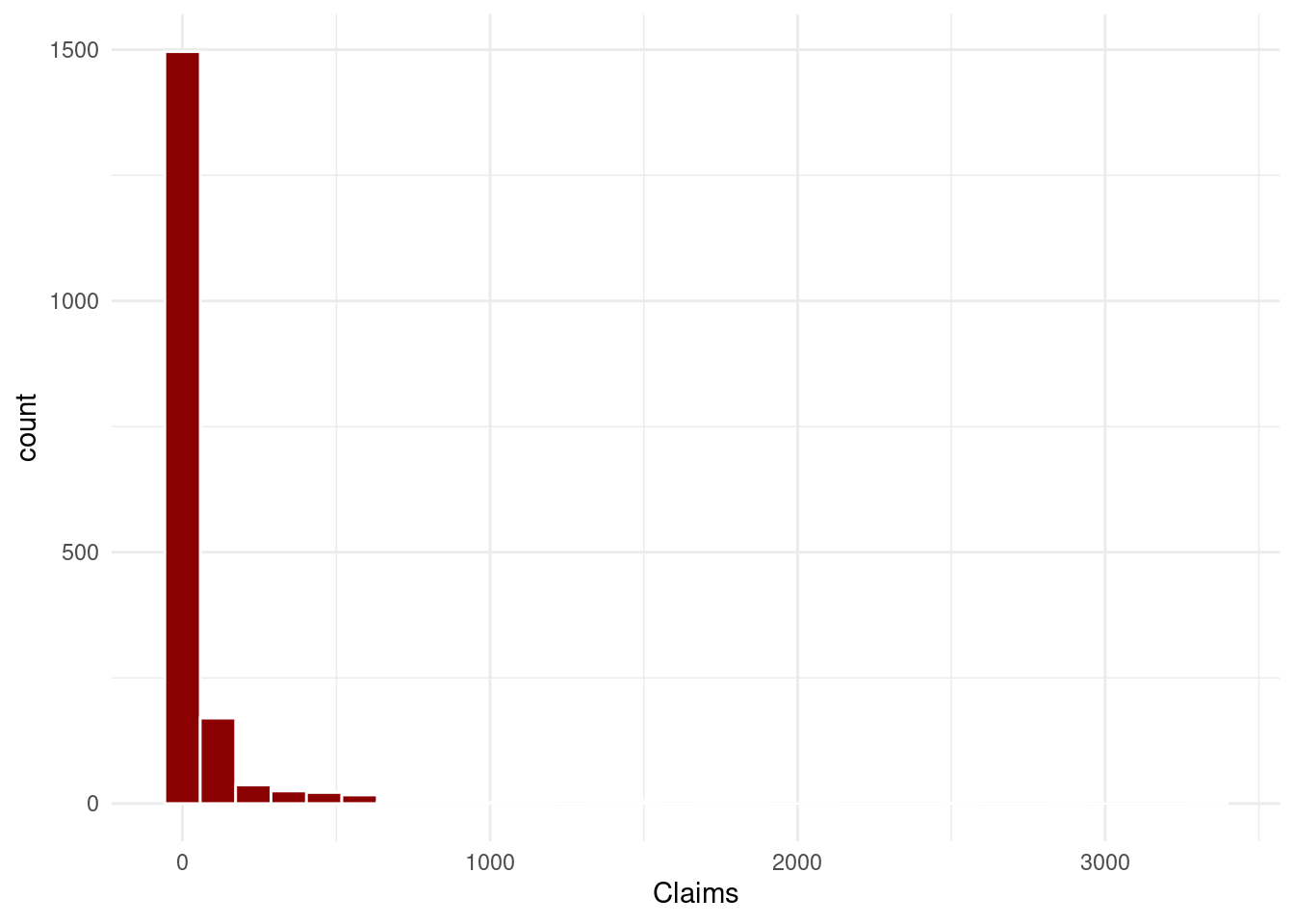
Vamos criar agora dois modelos, sendo o primeiro binomial negativo, similar ao que já fizemos anteriormente, utilizando as variáveis Zone e Maker. Iremos criar um modelo Binomial Negativo, Binomial Negativo com inflação de zeros e apenas para comparar, um OLS.
modelo_bneg_02_lmzip <- lm(formula = Claims ~ .,
data = df_zip)
modelo_bneg_02_nzip <- MASS::glm.nb(formula = Claims ~ .,
data = df_zip)
modelo_bneg_02_zip <- pscl::zeroinfl(formula = Claims ~ . | .,
dist = "negbin", data = df_zip)Podemos avaliar os logLik de ambos os modelos.
map_df(list(Bneg=modelo_bneg_02_nzip, Bneg_Zip=modelo_bneg_02_zip, OLS=modelo_bneg_02_lmzip), ~logLik(.))# A tibble: 1 × 3
Bneg Bneg_Zip OLS
<logLik> <logLik> <logLik>
1 -3824.124 -3231.998 -11943.81Aqui observamos que o modelo com inflação de zeros tem o maior logLik e portanto aparentemente melhor. Vejamos se estatisticamente melhor.
Podemos utilizar o teste de Vuong para comparar modelos de contagem com inflação de zeros e seus respectivos modelos sem inflação de zeros:
pscl::vuong(m1 = modelo_bneg_02_zip, m2 = modelo_bneg_02_nzip)Vuong Non-Nested Hypothesis Test-Statistic:
(test-statistic is asymptotically distributed N(0,1) under the
null that the models are indistinguishible)
-------------------------------------------------------------
Vuong z-statistic H_A p-value
Raw 24.76755 model1 > model2 < 2.22e-16
AIC-corrected 24.14013 model1 > model2 < 2.22e-16
BIC-corrected 22.41664 model1 > model2 < 2.22e-16Aqui, observamos que o modelo com inflações de zero binomial negativo, é estatisticamente mehor que o modelo sem inflações de zeros.
df_zip$fit_nzip <- predict(modelo_bneg_02_nzip, type = "response")
df_zip$fit_zip <- predict(modelo_bneg_02_zip, type ="response")
df_zip$fit_lmzip <- predict(modelo_bneg_02_lmzip, type ="response")
df$fit_nzip <- df_zip$fit_nzip
df$fit_zip <- df_zip$fit_zip
df$fit_lmzip <- df_zip$fit_lmzip
df |> dplyr::select(Claims, Zone, Make, fit_nzip, fit_zip, fit_lmzip) |>
ggplot(x=Zone, y=fit_nzip)+
geom_point(aes(x=Zone, y=Claims), color ="gray", alpha = 0.4)+
geom_point(aes(x=Zone, y=fit_lmzip), color = "blue") +
geom_point(aes(x=Zone, y=fit_nzip), color = "green") +
geom_point(aes(x=Zone, y=fit_zip), color = "red") +
facet_wrap(facets = vars(Make), scales = "free")+
theme_bw()+
labs(title = "Previsões por Zonas e Makers usando BNeg, BNeg \n com Inflações de Zeros e OLS", y = "Previsões", x = "Zone")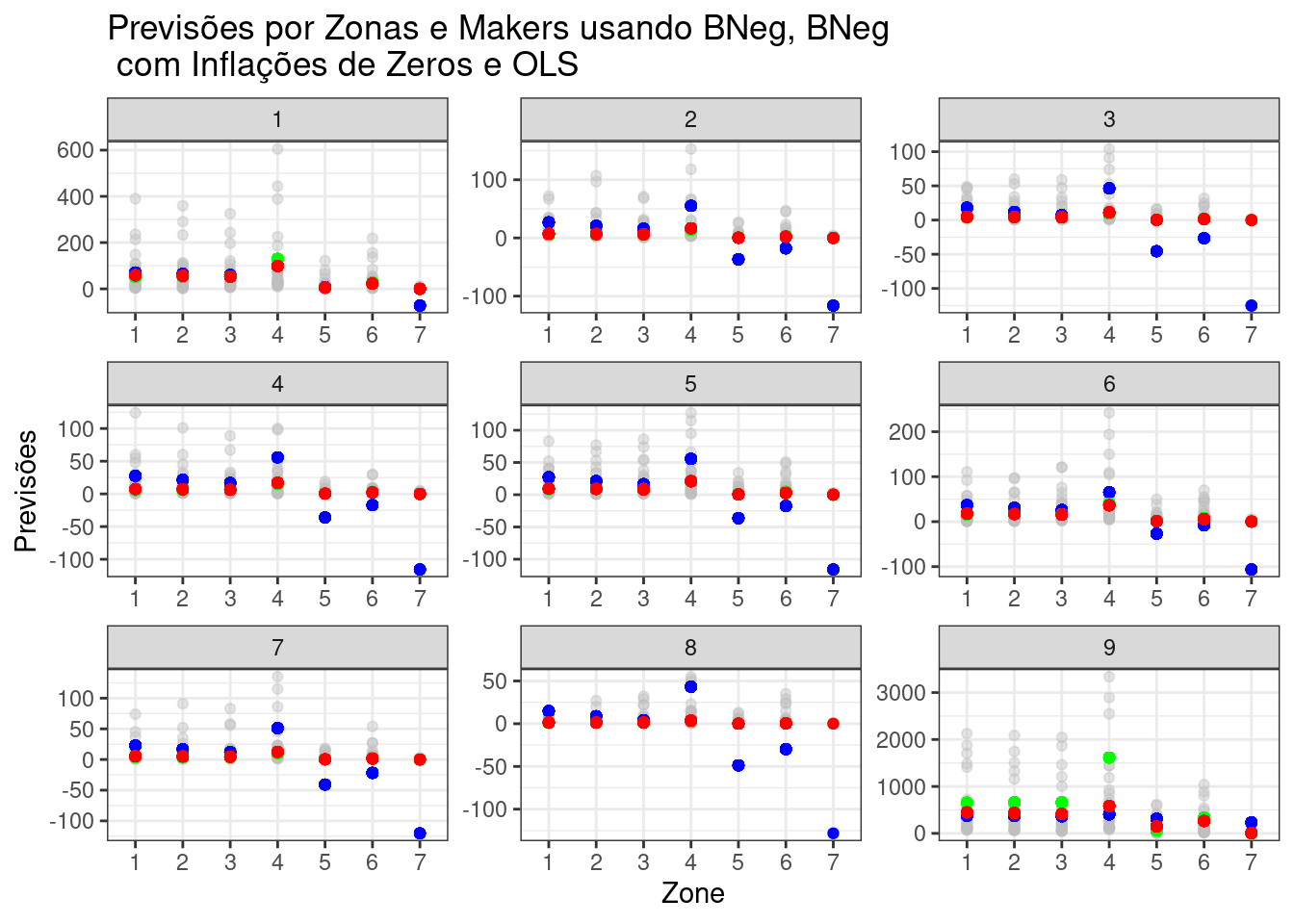
df |> dplyr::select(Claims, Zone, Make, fit_nzip, fit_zip) |>
pivot_longer(cols = c(fit_nzip, fit_zip),
names_to = "modelo",
values_to = "previsão") |>
ggplot(aes(x=Claims, y=previsão, color=modelo))+
geom_smooth(method = "loess",se = T)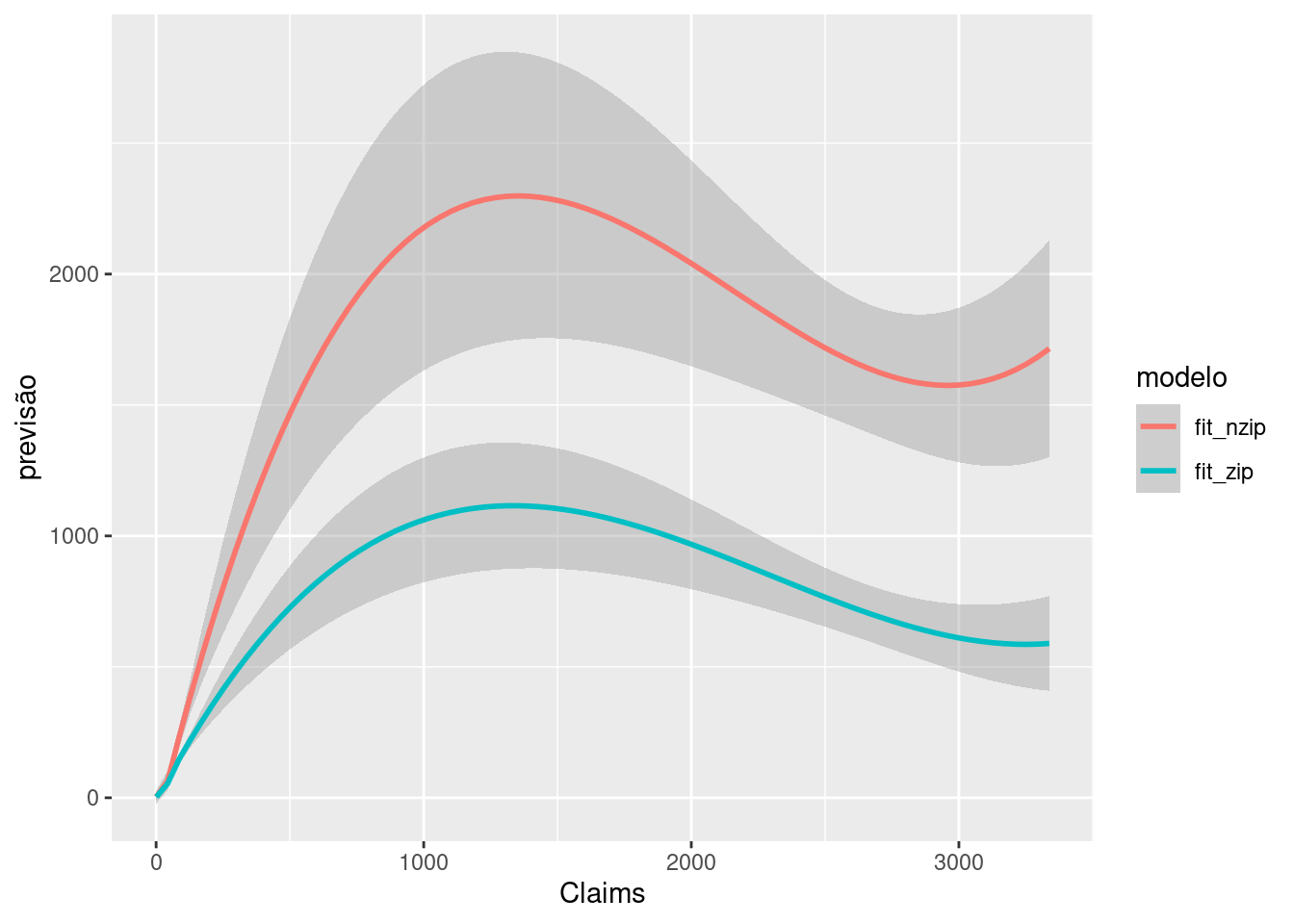
A seguir, iremos apresentar as distribuições teóricas poisson, binomial negativa para referência:
# A DISTRIBUIÇÃO POISSON
#Estabelecendo uma função da distribuição Poisson com lambda = 1
poisson_lambda1 <- function(m){
lambda <- 1
(exp(-lambda) * lambda ^ m) / factorial(m)
}
#Estabelecendo uma função da distribuição Poisson com lambda = 4
poisson_lambda4 <- function(m){
lambda <- 4
(exp(-lambda) * lambda ^ m) / factorial(m)
}
#Estabelecendo uma função da distribuição Poisson com lambda = 10
poisson_lambda10 <- function(m){
lambda <- 10
(exp(-lambda) * lambda ^ m) / factorial(m)
}
#Plotagem das funções estabelecidas anteriormente
data.frame(m = 0:20) %>%
ggplot(aes(x = m)) +
stat_function(fun = poisson_lambda1, size = 1.5,
aes(color = "01")) +
stat_function(fun = poisson_lambda4, size = 1.5,
aes(color = "04")) +
stat_function(fun = poisson_lambda10, size = 1.5,
aes(color = "10")) +
scale_color_discrete("Valores de" ~ lambda ~ "") +
labs(title = "Função Massa Probabilidade (Poisson)", y = "Probabilidades", x = "m")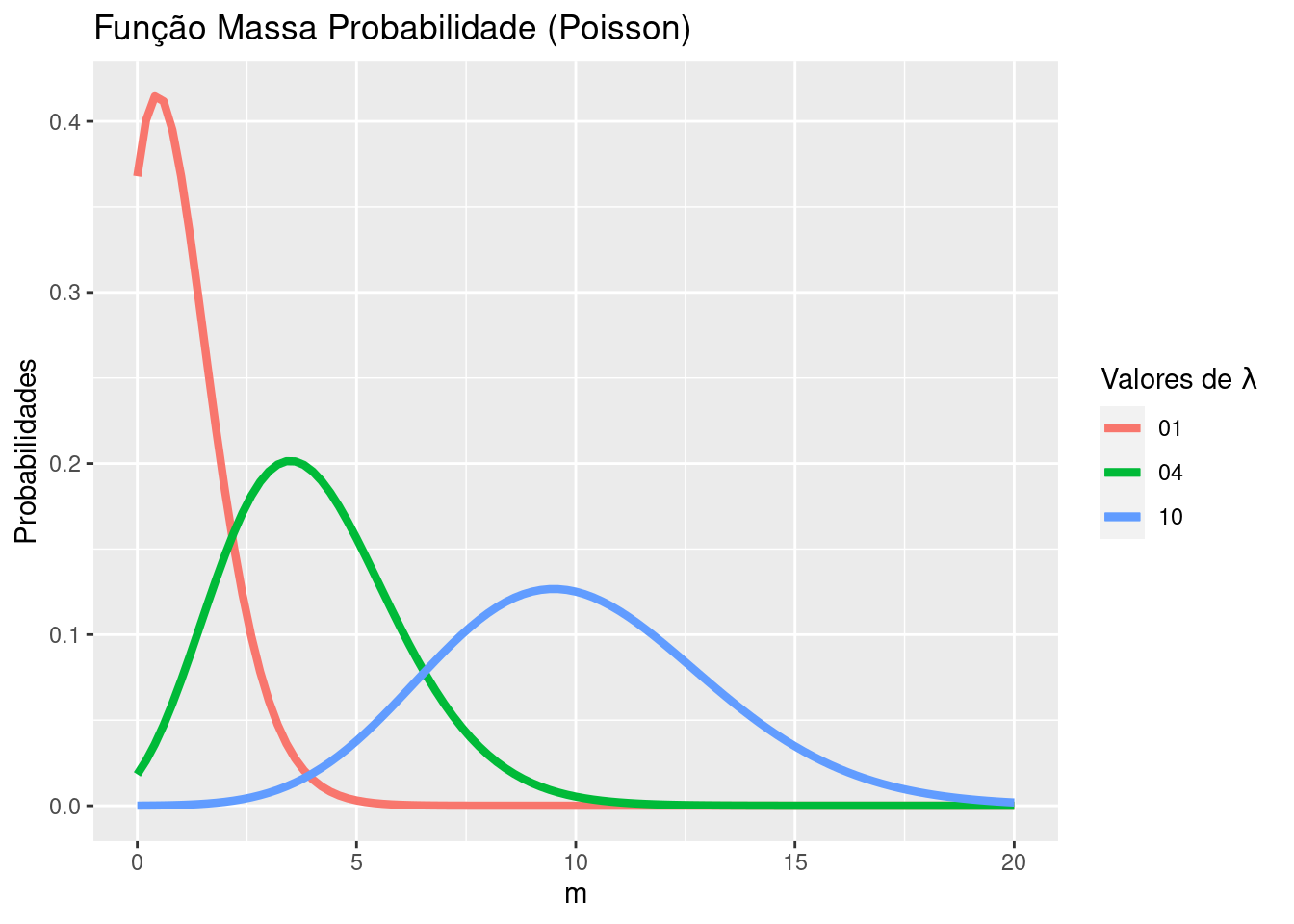
# A DISTRIBUIÇÃO BINOMIAL NEGATIVA - PARTE CONCEITUAL
#Criando com theta=2 e delta=2
#theta: parâmetro de forma da distribuição Poisson-Gama (binomial negativa)
#delta: parâmetro de taxa de decaimento da distribuição Poisson-Gama
bneg_theta2_delta2 <- function(m){
theta <- 2
delta <- 2
((delta ^ theta) * (m ^ (theta - 1)) * (exp(-m * delta))) / factorial(theta - 1)
}
#Criando uma função da distribuição binomial negativa, com theta=3 e delta=1
bneg_theta3_delta1 <- function(m){
theta <- 3
delta <- 1
((delta ^ theta) * (m ^ (theta - 1)) * (exp(-m * delta))) / factorial(theta - 1)
}
#Criando uma função da distribuição binomial negativa, com theta=3 e delta=0,5
bneg_theta3_delta05 <- function(m){
theta <- 3
delta <- 0.5
((delta ^ theta) * (m ^ (theta - 1)) * (exp(-m * delta))) / factorial(theta - 1)
}
#Plotagem das funções estabelecidas anteriormente
data.frame(m = 1:20) %>%
ggplot(aes(x = m)) +
stat_function(fun = bneg_theta2_delta2,
aes(color = "Theta igual a 2 e Delta igual a 2"),
size = 1.5) +
stat_function(fun = bneg_theta3_delta1,
aes(color = "Theta igual a 3 e Delta igual a 1"),
size = 1.5) +
stat_function(fun = bneg_theta3_delta05,
aes(color = "Theta igual a 3 e Delta igual a 0,5"),
size = 1.5) +
scale_color_discrete("Valores de " ~ theta ~ "e " ~ delta ~ "") +
labs(title = "Função Massa Probabilidade (Binomial Negativa)", y = "Probabilidades", x = "m")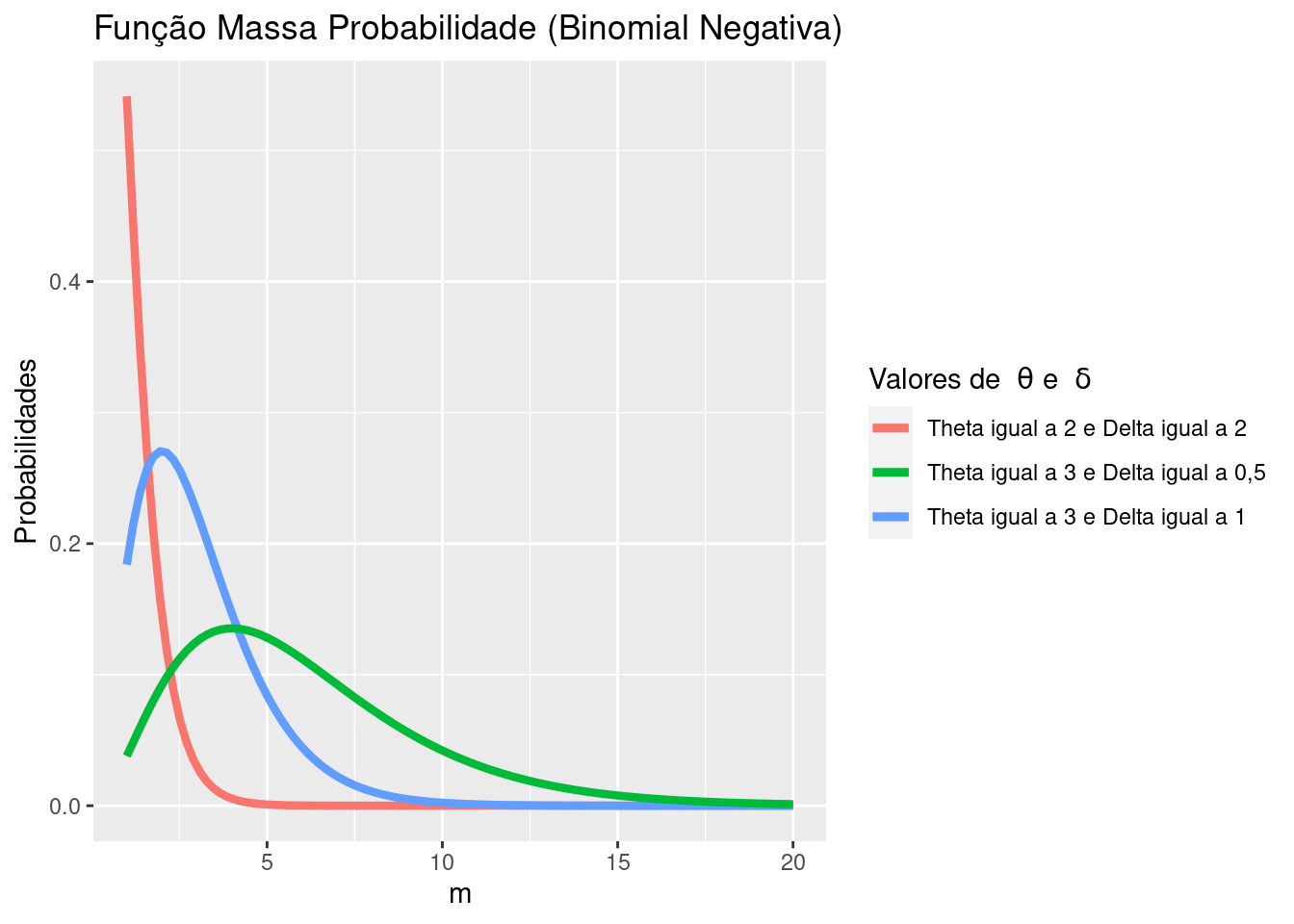
# A DISTRIBUIÇÃO ZERO-INFLATED POISSON (ZIP)
#Exemplo de uma função da distribuição ZI Poisson, com lambda = 1 e plogit = 0,7
zip_lambda1_plogit07 <- function(m){
lambda <- 1
plogit <- 0.7
ifelse(m == 0,
yes = (plogit) + ((1 - plogit) * exp(-lambda)),
no = (1 - plogit) * ((exp(-lambda) * lambda ^ m) / factorial(m)))
}
#Comparando as distribuições Poisson, BNeg e ZIP
data.frame(m = 0:20) %>%
ggplot(aes(x = m)) +
stat_function(fun = zip_lambda1_plogit07, size = 1.5,
aes(color = "ZIP - Lambda igual a 1 e plogit igual a 0,7")) +
scale_color_discrete("Distribuição:") +
labs(title = "Função Massa Probabilidade (Poisson Zero Inflated)",y = "Probabilidade", x = "m") +
theme (legend.position = "bottom")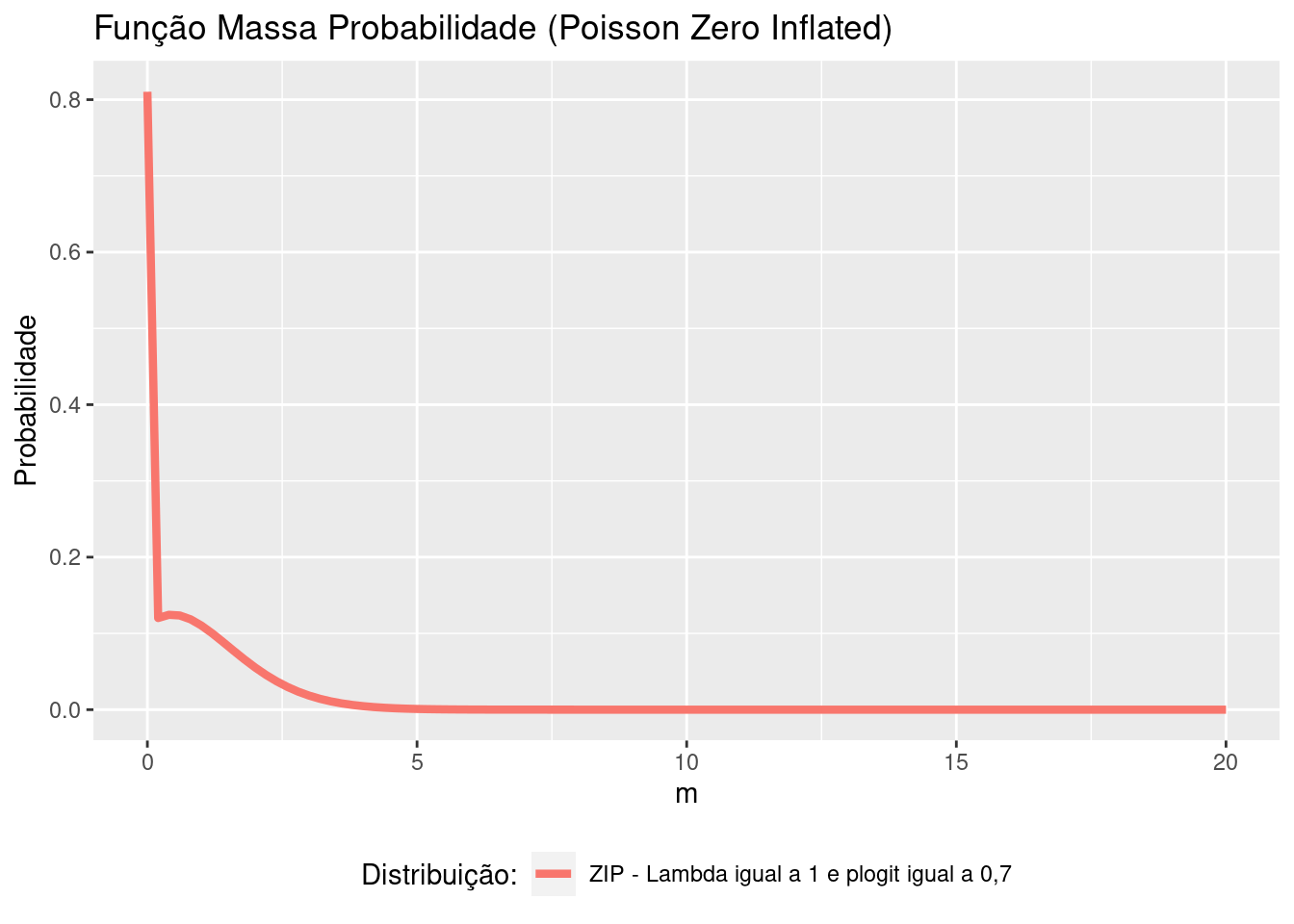
# DISTRIBUIÇÃO ZERO-INFLATED BINOMIAL NEGATIVA (ZINB)
#Exemplo de uma função da distribuição ZI Binomial Negativa, com theta = 2,
#delta = 2, plogit = 0,7 e lambda_bneg = 2
zinb_theta2_delta2_plogit07_lambda2 <- function(m){
theta <- 2
delta <- 2
plogit <- 0.7
lambda_bneg <- 2
ifelse(m == 0,
yes = (plogit) + ((1 - plogit) * (((1) / (1 + 1/theta * lambda_bneg)) ^ theta)),
no = (1 - plogit) * ((delta ^ theta) * (m ^ (theta - 1)) *
(exp(-m * delta))) / factorial(theta - 1))
}
#Comparando as distribuições Poisson, BNeg, ZIP e ZINB
data.frame(m = 0:20) %>%
ggplot(aes(x = m)) +
stat_function(fun = zinb_theta2_delta2_plogit07_lambda2, size = 1.5,
aes(color = "ZINB - Theta igual a 2, Delta igual a 2 e plogit igual a 0,7")) +
scale_color_discrete("Distribuição:") +
labs(title = "Função Massa Probabilidade (Bineg Zero Inflated)", y = "Probabilidade", x = "m") +
theme_bw()+
theme(legend.position = "bottom")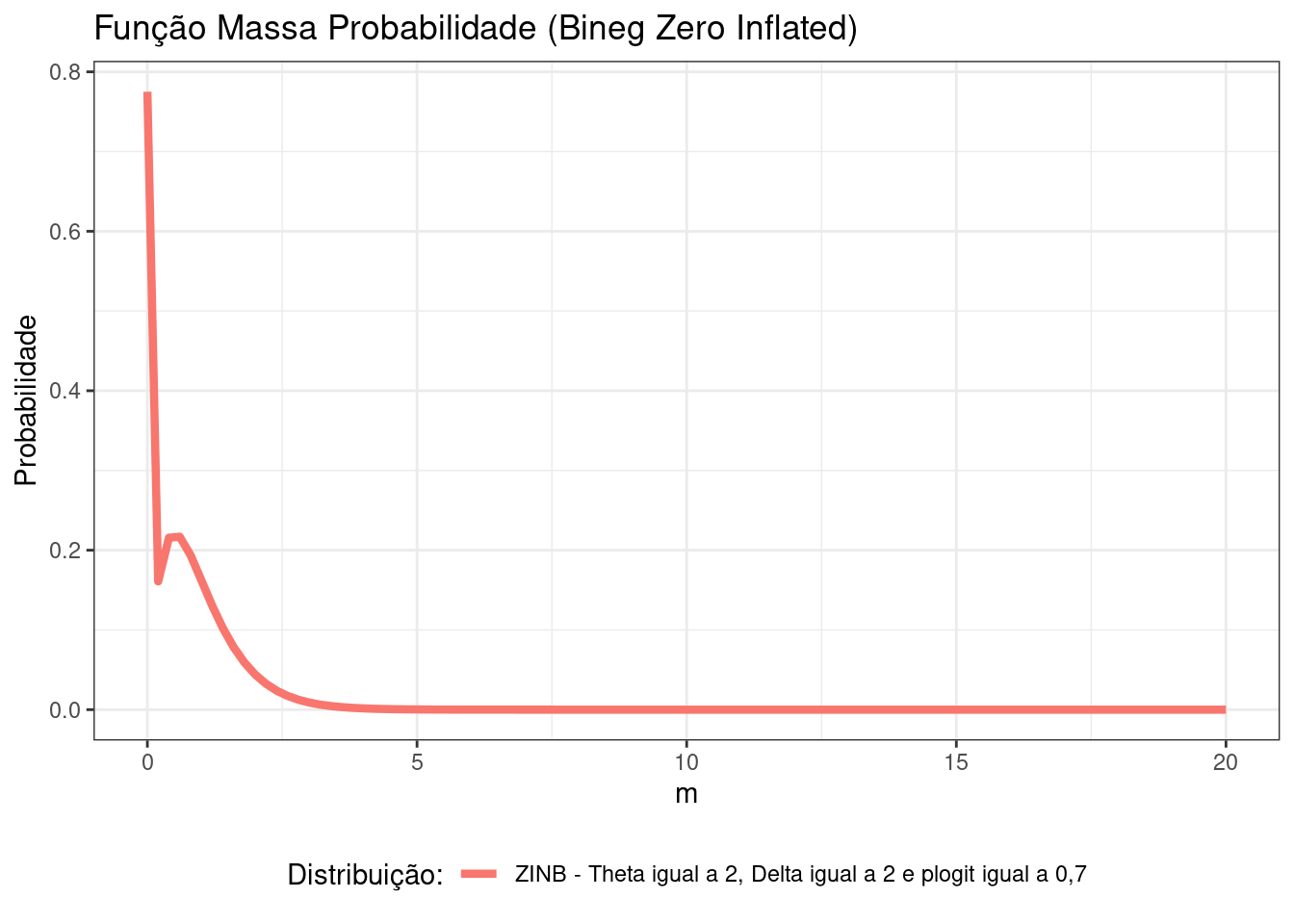
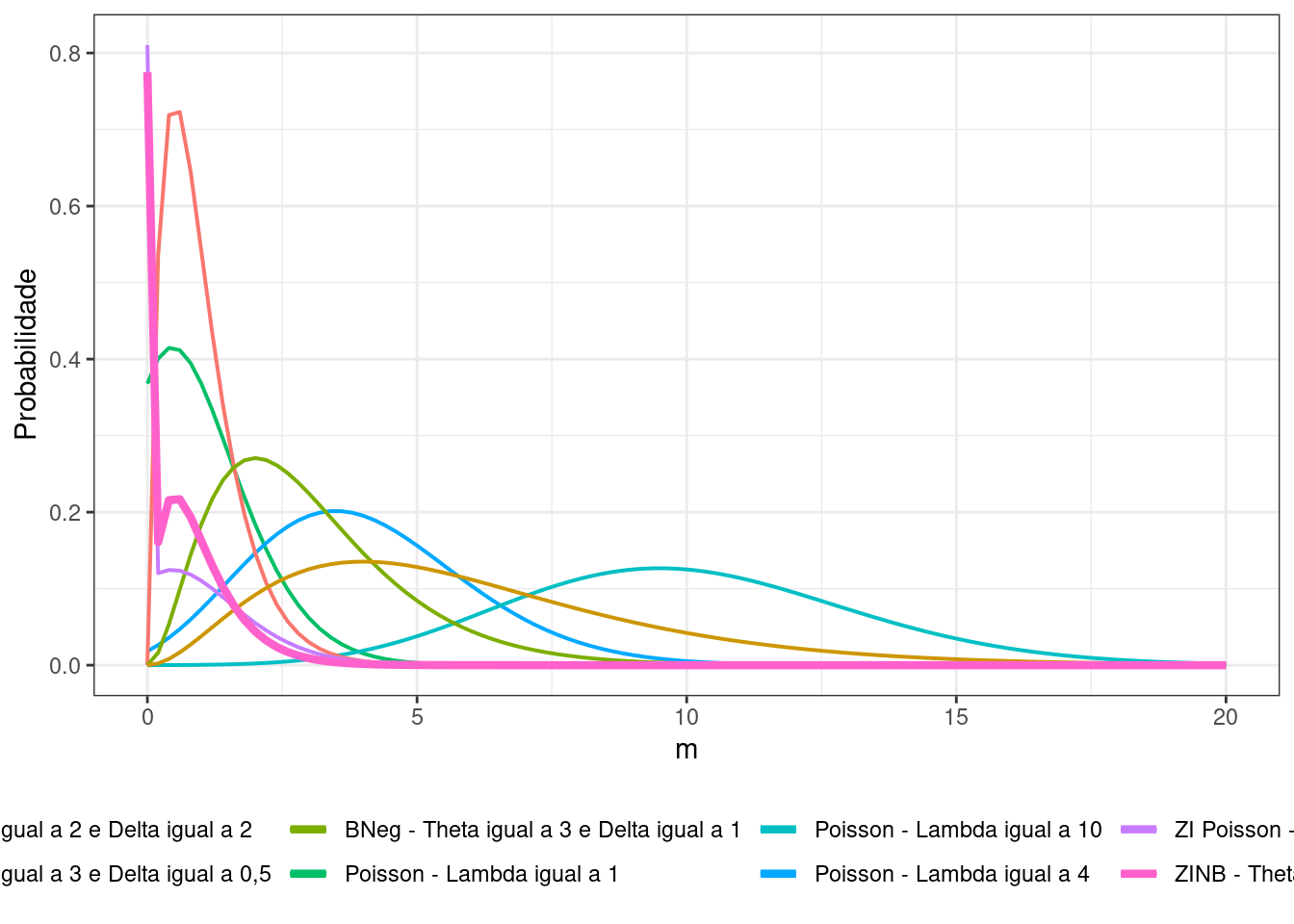
data.frame(m = 0:20) %>%
ggplot(aes(x = m)) +
stat_function(fun = poisson_lambda1, size = 0.7,
aes(color = "Poisson - Lambda igual a 1")) +
stat_function(fun = poisson_lambda4, size = 0.7,
aes(color = "Poisson - Lambda igual a 4")) +
stat_function(fun = poisson_lambda10, size = 0.7,
aes(color = "Poisson - Lambda igual a 10")) +
stat_function(fun = bneg_theta2_delta2, size = 0.7,
aes(color = "BNeg - Theta igual a 2 e Delta igual a 2")) +
stat_function(fun = bneg_theta3_delta1, size = 0.7,
aes(color = "BNeg - Theta igual a 3 e Delta igual a 1")) +
stat_function(fun = bneg_theta3_delta05, size = 0.7,
aes(color = "BNeg - Theta igual a 3 e Delta igual a 0,5")) +
stat_function(fun = zip_lambda1_plogit07, size = 0.7,
aes(color = "ZI Poisson - Lambda igual a 1 e plogit igual a 0,7")) +
stat_function(fun = zinb_theta2_delta2_plogit07_lambda2, size = 1.5,
aes(color = "ZINB - Theta igual a 2, Delta igual a 2 e plogit igual a 0,7")) +
scale_color_discrete("Distribuição:") +
labs(y = "Probabilidade", x = "m") +
theme_bw()+
theme(legend.position = "bottom")